Audio Science Review Forum - Analyse eines Diskussionsforums


Dieser Blogbeitrag beschäftigt sich mit Data-Mining und beinhaltet die Erfassung, sowie Einordnung großer Datenmengen. Die Daten werden in ein Muster gebracht und in Beziehungen zueinander gestellt. Folgende Data-Mining-Techniken sind im Projekt umgesetzt worden:
- Datensatz erstellen (Datenabzug)
- Einstufung der Daten
- Gruppierte Datensätze erstellen
- Clustering
- Zeitreihenanalysen
- Prognosemethoden
- Interpretation der ausgewerteten Daten
Die Ergebnisse dieser Analysen entstanden im Rahmen der Projektarbeit 'ASR Mining' im Fach Data Science von Prof. Dr. Bastian Beggel.
Projektziel sowie Aufbau
In diesem Projekt haben wir die Daten des Audio Science Review Diskussionsforums abgezogen und entsprechend analysiert. Die daraus gewonnen Informationen sollen Aufschluss über die User, deren Regionen, deren Threads, die Trends, sowie die saisonalen Effekte liefern.
Dieser Blogbeitrag soll neben der Dokumentation auch eine Hilfestellung zur Herangehensweise von ASR Mining insbesondere auf Bezug von Foren bieten.
Was ist das Audio Science Review?
Audio Science Review (ASR) ist ein Diskussionsforum, welches sich auf die Technik von Audiogeräten konzentriert. Es bietet umfangreiche Bewertungen und Tests von Audio-Ausrüstungen, einschließlich Lautsprechern, Verstärkern, Kopfhörern und weiteren Geräten.
Es beinhaltet drei große Diskussionsbereiche. Im Hauptforum wird über 'Lautsprecher', sowie Messungen und deren Bewertungen diskutiert. Zusätzlich unterstützen Expertenmitglieder täglich bei der Bewertung. In diesem Diskussionsforum ist fachliche Expertise erwünscht.
Die anderen großen Diskussionsbereiche beinhalten die Themen 'Musik- und Filmdiskussionen', sowie 'Andere' Interessensgebiete.
Audio Science Review ist für Neulinge bis Experten von Audiogeräte geeignet, um sich weiterzubilden oder über zwanglose Themen zu diskutieren und Hilfe zu finden in diesen Themenbereichen.
Der Abzug der Daten mit Beautiful Soup
Um die Daten des Forums abzugreifen, haben wir ein Programm mit der Sprache Python weiterentwickelt, welches sich an der freien Bibliothek Beautiful Soup bedient. Diese Programmbibliothek ermöglicht das Screen Scraping von beliebigen Webseiten aus XML- und HTML-Dokumenten. Die Daten können dann in einer externen Datei abgespeichert werden.
from bs4 import BeautifulSoupUm die Daten abzugreifen, muss eine Anfrage erstellt. Diese wird empfangen und mit Beautiful Soup geparst.
result = requests.get("https://www.audiosciencereview.com/forum/index.php?threads/" + str(threadCounter) + "/page-" + str(pageCounter))
src = result.content
result.close()
soup = BeautifulSoup(src, "html.parser")Anschließend werden die gewünschten Daten aus der gespeicherten Webpage ausgelesen. Im Beispiel hier wird die Thread-ID ausgelesen.
thread = soup.find("html").attrs["data-content-key"]Da die Abrufung der Daten sehr zeitintensiv ist, muss einiges umgeschrieben und beachtet werden, um so wenig neue Seiten wie möglich abzurufen. Hierfür wird zum Beispiel die Fremdseite mit der Auflistung der Likes nur abgerufen, wenn die Namen der Liker nicht mehr vollständig im Post angezeigt werden. Dann steht in der Auflistung 'others'.
substring = "others"
#Ausgabe ohne others
if substring not in likers.text: #Code
#Ausgabe mit others
if substring in likers.text: #Code
Um von dem Server nicht blockiert zu werden, muss nach jeder abgegriffenen Seite eine kurze Pause von wenigen Sekunden integriert werden.
Die Daten eines Posts, eines Forums und der Likes werden in jeweils externe CSV-Dateien abgespeichert.
Analyse der Daten mit R
Die Top User
Um mehr über die User des Forums herauszufinden, haben wir uns die Top 10 User mit den meisten Beiträgen einmal genauer angeschaut. Bei einigen Usern kann man deren Interessen deutlich erkennen.
Zuerst werden die Daten in R eingebunden und etwas angepasst. Aus der Variable Date, werden der Tag, Monat, Jahr, … ausgelesen und in separaten Spalten gespeichert.
asr$day <- as.factor(weekdays(as.Date(asr$date)))Anschließend werden die Datensätze des gewünschten Top-Users ausgelesen und in einen neuen Dataframe gespeichert. Im Beispiel hier picken wir uns den User mit dem Namen Solderdude heraus.
asrSolderdude = subset(asr, member=="solderdude")Im Datensatz asr sind allerdings nur die Thread-IDs abgespeichert, denn der Name des Threads, sowie deren Subkategorien sind in einer externen Datei gespeichert. Um diese nun zusammenzuführen, wird die merge-Funktion verwendet. Anhand der Variable thread wird diese dann zusammengeführt.
asrSolderdudeThreads = merge(x = asrSolderdude, y = asrThreads, by = "thread", all.x = TRUE)Beim Datenabgriff wurden die Subforen alle in eine Spalte gepackt und mit einem Semikolon getrennt. Um nur die obere Kategorie aus dem Datensatz zu erhalten, die Subkategorie, müssen die unteren herausgelöscht werden. Dies wurde mit der gsub-Funktion umgesetzt. Mithilfe von regulären Ausdrücken kann dies umgesetzt werden.
asrSolderdudeThreads$subforums <- gsub(".;","",as.character(asrSolderdudeThreads$subforums))Daraufhin werden die Subkategorien gezählt und die Ergebnisse in ein neues Dataframe gespeichert. Die entsprechenden Spalten kommen mit automatisch erzeugten Namen heraus und werden deshalb noch umbenannt in count und subforums. Wobei count die Anzahl der Posts in dieser Subkategorie sind und subforum der Name dieser.
df = data.frame (first_column = table(asrSolderdudeThreads['subforums']))
colnames(df)[which(names(df) == "first_column.Freq")] <- "count"
colnames(df)[which(names(df) == "first_column.subforums")] <- "subforums"Anschließend werden die Top 10 Subkategorien mit den meisten Posts herausgenommen und abgespeichert. Der Plot kann nun erstellt werden. Hierzu wurde geom_bar ausgewählt und die Balken nach Größe der meisten Posts sortiert. In der y-Achse haben wir die Namen der Subkategorien und in der x-Achse die Anzahl der Posts.
CountOrder = df[order(-df$count),]
CountOrder = CountOrder[0:10,]
ggplot(CountOrder, aes(y=reorder(subforums, +count),x=count)) +
geom_bar(color="white", fill="steelblue",stat='identity') +
labs(x="Anzahl der Posts", y="Name der Kategorie") +
ggtitle("Top 10 Kategorien von Solderdude")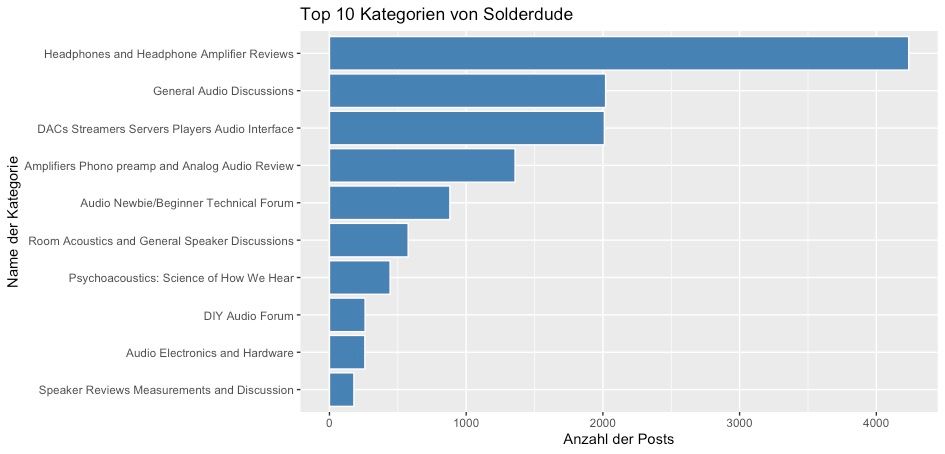
Hier ist deutlich zu erkennen, dass der User mit seinen Top-Subkategorien sehr stark an dem Thema Headphones interessiert ist. Über 4.200 Posts hat er in seinem Top Thread abgeschickt.
Erwähnt werden muss noch, dass dies lediglich die Top 10 Subkategorien sind und wenn man die restlichen zusammenzählt, kommt man auf insgesamt 430 Posts in den anderen Subkategorien, welche nicht aufgelistet wurden. Dennoch sind seine Beiträge insgesamt über 42 % in Subkatergorien mit dem Thema Kopfhörer.
Auch beim Betrachten der direkten Top-Threads ist uns etwas Interessantes aufgefallen. Einige der Top-User posten sehr viel in den Social-Threads ihren Beitrag.
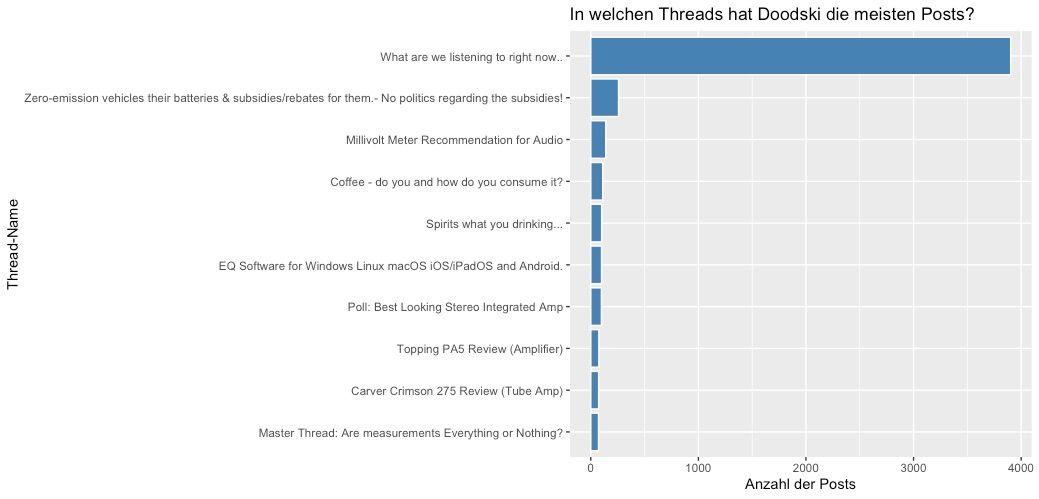
Der Top-User Doodski hat insgesamt ca. 14.800 Posts in das Forum gepostet. Fast 4.000 davon sind im Thread "What are we listining to right now". In diesem Thread werden lediglich die aktuellen Lieder, welche die User hören, hineingepostet.
Klingt viel, sind aber lediglich 27 % der gesamten Aktivität des Users. Seine Threads sind ansonsten sehr unterschiedlich und weit gefächert.
Zeitreihenanalyse (Time Series)
Die Zeitreihenanalyse ist ein wichtiger Bestandteil der statistischen Datenanalyse in R und ermöglicht es, zeitabhängige Daten zu untersuchen und zu modellieren.
Dies gibt Aufschluss über Trends, saisonale Effekte oder zukünftige Prognosen. R stellt mehrere Pakete bereit, die für die Zeitreihenanalyse verwendet werden können. Die wichtigsten sind das ts-, prophet- und das forecast-Paket. In dem Blogbeitrag wird näher auf die Ts-, Decompose- und Holt-Winters-Methoden eingegangen.
Um einen aussagekräftigen Graphen zu erhalten, ist eine geeignete Formatierung des Dataframes notwendig. Dies beinhaltet das Aufbereiten der Daten in ein Zeitreihenformat, das Entfernen von fehlenden Werten und das Identifizieren und Behandeln von Ausreißern.
asr <- asr[ which( asr$month != 12 | asr$year != 2022) , ]Die obige Codezeile entfernt die Daten von November 2022 und Dezember 2022, da der Datenabzug im November durchgeführt wurde und ohne eine Bereinigung, die Ergebnisse verfälschen würde.
CountDF <- ddply(asr, c("year", "month"), .fun=function(zz)
data.frame(nbr=nrow(zz)))
dfp <- ts(CountDF$nbr, freq = 12, start = 2016)
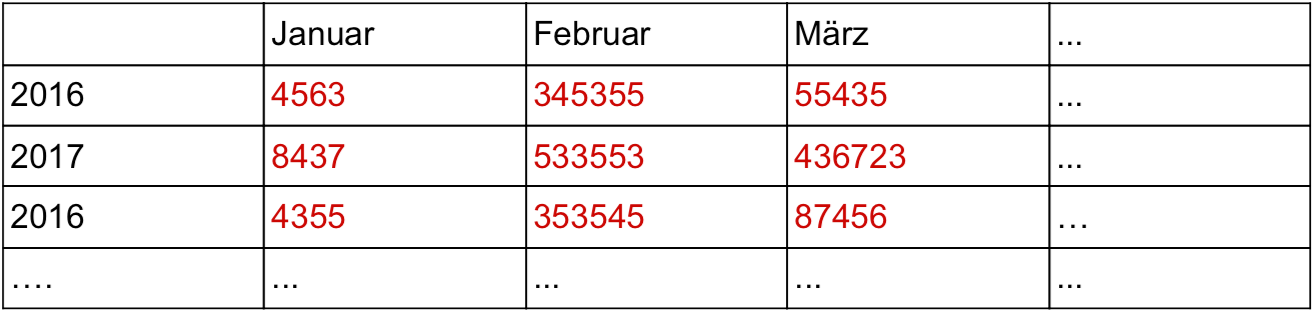
dfpNach der Bereinigung des Datensatzes wird eine Tabelle erstellt, welche optimale Ergebnisse für die Zeitreihenanalyse erzeugt.
Es ist auch von Bedeutung, die Art der Zeitreihe zu identifizieren, wie zum Beispiel, ob es sich um einen saisonalen Effekt handelt oder ob ein Trend dahingehend existiert. Im Projekt ist unter anderem ein Dataframe erstellt worden, welcher die Summe der Posts von jedem Monat und Jahr auflistet (siehe Tabelle). Ist der Datensatz vorbereitet, kann die Zeitreihe analysiert werden, indem verschiedene statistische Methoden angewendet werden. Die ARIMA-Modellierung kann mit der plot.ts()-Funktion angewendet werden. Diese Modellierung wird verwendet, um Trends und saisonale Effekte zu identifizieren und zu modellieren.
Die Zeitreihenanalyse besteht aus den verschiedenen Komponenten:
- dem Trend
- der saisonale Effekt
- zufällige Schwankungen
Auf Abbildung 4 ist der ursprüngliche Graph in drei weitere Sektionen aufgeteilt und stellt die einzelnen Ausprägungen bereinigt dar. Die Achsen werden richtig interpretiert und geben einen aussagekräftigen Graphen aus.
time_series_components <- decompose(dfp)
plot(time_series_components, xlab="year")Die decompose-Funktion erstellt den aufgeführten Plot und separiert die enthaltenen Effekte.
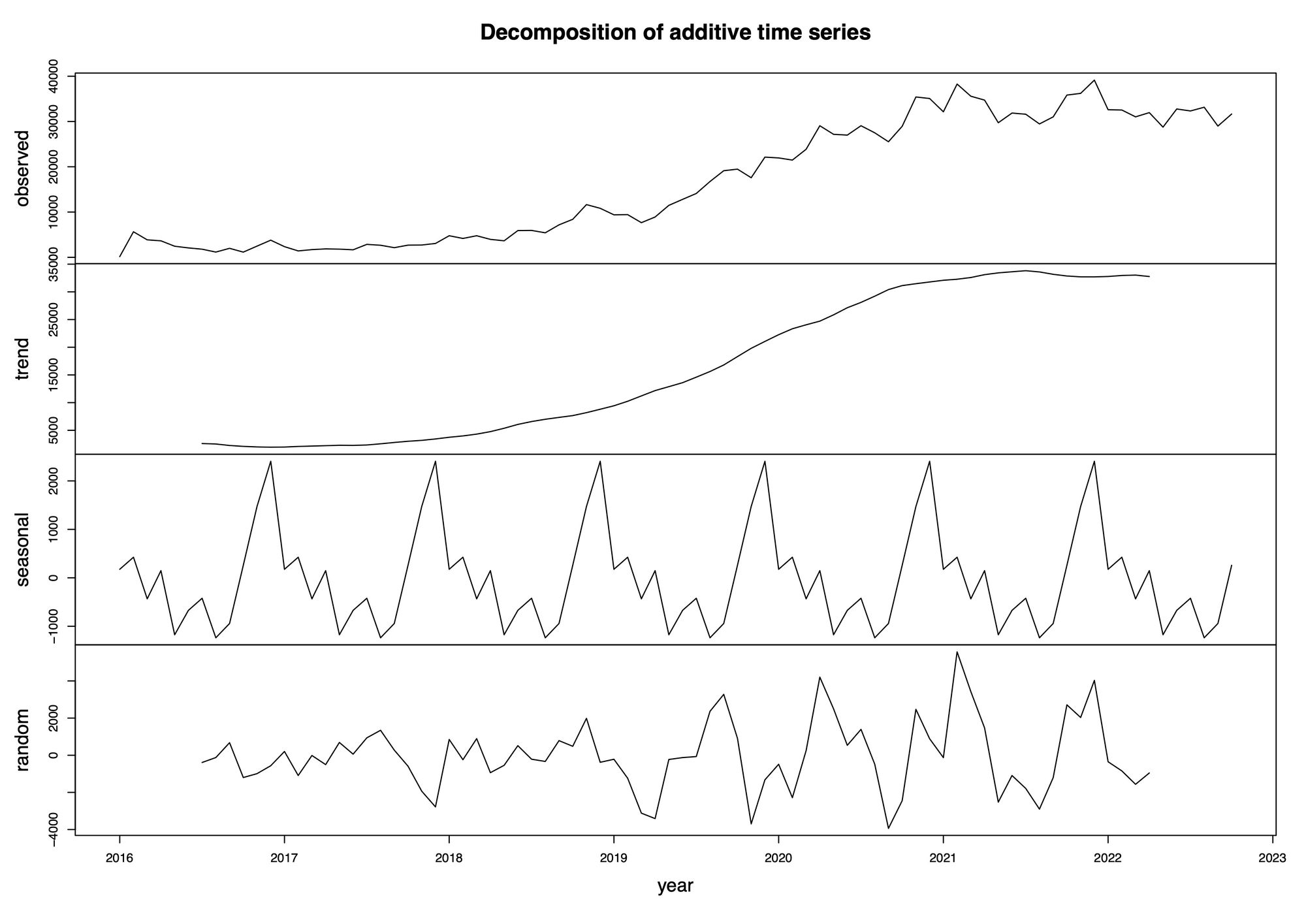
In der ersten Zeile befindet sich der unbereinigte Graph, die ARIMA-Modellierung, aus dem bereits ein steigender Trend des ASR-Forums erkennbar ist. Denn die Anzahl an Posts nehmen jährlich zu.
Noch ersichtlicher ist das in der zweiten Zeile (Trend) zu entnehmen.
Der saisonale Effekt in der dritten Zeile kann nicht eindeutig interpretiert werden, da in der vierten Zeile die zufälligen Schwankungen sehr stark sind, welche die sonstigen Einflüsse und Störungen zusammenfassen. Diese Schwankungen sind während der Hochphase der Coronakrise größer, was daran liegen könnte, dass die Benutzer in dieser Zeit aktiver waren.
Weitere Analysen können mit dem Holt-Winters-Verfahren durchgeführt werden. Durch dieses Verfahren können Vorhersagen modelliert und Prognosen für die zukünftige Aktivität auf dem ASR-Forum erstellt werden. Es ist wichtig, die Genauigkeit dieses Verfahrens zu überprüfen, indem die tatsächlichen und prognostizierten Werte verglichen werden.
Regionen der User (Time Cluster)
Um die Regionen der User herauszufinden, haben wir zuerst ein passendes Dataframe aufgebaut, um ein entsprechendes Cluster erstellen zu können.
Die Idee dabei ist es, anhand der Uhrzeiten die Regionen zu erkennen. Die Uhrzeiten sind die, zu welchen der entsprechende User seine Posts abschickt. Anhand der Zeitzonen sollen dann die Regionen ungefähr zugeordnet werden.
Zuerst haben wir die Top 100 User ausgewählt, um erstmal eine Übersicht zu erlangen. Hierfür wurden alle User mit über 2220 Posts ausgewählt und die Namen derer in eine Liste gepackt.
NumberPosts <- ddply(asr, c("member"), .fun=function(zz) data.frame(nbr=nrow(zz)))
data = subset(NumberPosts, nbr>2220)
mylist=list(member=data)
mylist = mylist[["member"]][["member"]]
Anschließend wird anhand dieser erzeugten Liste das richtige Dataframe erzeugt. Hierzu werden alle User ausgesucht, welche in dieser Liste vorkommen, und schließlich in ein neues Dataframe gespeichert.
asrTop1000 <- asr[asr$member %in% mylist, ]Nun werden die Posts in eine Tabelle anhand der Stunden gepackt. Von 0 bis 23 Uhr und die jeweilige Anzahl der Posts der User.
xx=table(as.character(asrTop1000[,"member"]),asrTop1000[,"hour"])Die Daten werden in ein für das Plotten des Clusters vorbereitet. Hierfür wird die dist()-Funktion verwendet, um eine Entfernungsmatrix zu berechnen. Diese zeigt die Abstände zwischen den Zeilen eines Dataframes an.
Anschließend wird eine hierarchische Clusteranalyse durchgeführt. Der Algorithmus dieser Methode sortiert jedes Objekt seinem eigenen Cluster zu. Danach fährt dieser Algorithmus iterativ fort und fügt bei jedem Durchgang die beiden ähnlichsten Cluster zusammen, bis es nur noch einen einzigen Cluster gibt. Die Abstände zwischen den Clustern werden durch den Lance-Williams-Algorithmus berechnet.
distMat = dist(xx, method="euclidean")
Hierar_cl <- hclust(distMat, method = "average")Die Daten werden nun in eine Matrix gepackt und als solche dargestellt. Mit der apply()-Funktion wird die Matrix als ein Array ausgegeben. Die 1 gibt hierfür an, dass die Manipulation an den Zeilen durchgeführt wird und nicht an den Spalten. Als Funktion soll die Summe angewendet werden.
matrixxx = as.matrix(xx)
mat_norm=matrixxx/apply(matrixxx, 1, sum)Anschließend wird nochmals die Entfernungsmatrix berechnet, sowie die hierarchische Clusteranalyse durchgeführt.
distMat = dist(mat_norm, method="euclidean")
Hierar_cl <- hclust(distMat, method = "average")Nun kann der erzeugte Datensatz geplottet werden.
plot(Hierar_cl)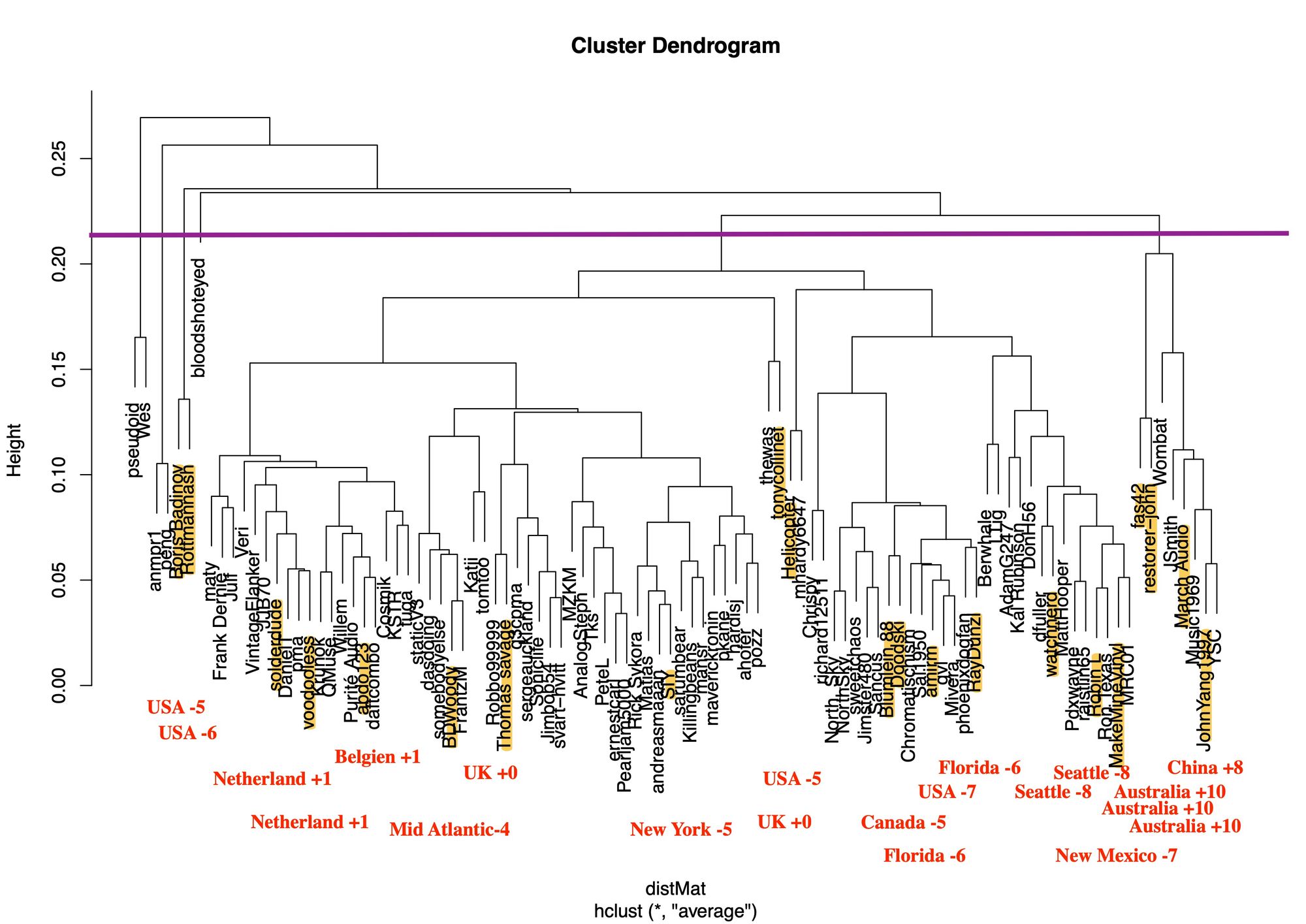
Anschließend haben wir im Forum nachgeschaut, bei welchen User die Region bereits im öffentlichen Nutzer-Profil angegeben war. So konnten wir den Standort einiger User herausfinden und in das Bild mit integrieren.
Dadurch konnten wir die Regionen etwas zuordnen. Auf der linken Seite befindet sich die USA mit der Zeitzone -5 und -6. Diese beiden Punkte scheinen jedoch Ausreißer zu sein, da diese Zeitzone nochmals auftauchen wird.
Anschließend kommt Europa mit den Zeitzonen +1 und +0. Je weiter rechts man geht, desto mehr gehen die Zahlen der Zeitzonen nach unten.
Dieses Cluster kann man der Zeitzone Amerika zuweisen.
Ab einem gewissen Punkt springt es dann in die nächste Zeitzone mit +10, welches in der Region Australien und China beinhaltet.