AWS DeepRacer


Introduction to DeepRacer
This project was part of the course 'Deep Learning' at University of Applied Sciences Kaiserslautern. The topic of the summer term 2022 was 'Reinforcement Learning' and this is our approach to combine the topic with vehicles. After a research which projects are already available and fulfil our requirements, we stumbled across AWS DeepRacer.
The AWS DeepRacer is a beginner-friendly ecosystem for dealing with the topics of machine learning, reinforcement learning and autonomous vehicles. The physical DeepRacer is a model in scale 1:18, equipped with various sensors in order to solve tasks such as obstacle detection or recognize a racetrack after appropriate training.
As the name suggests, the DeepRacer relies on AWS, Amazon's in-house cloud platform. However, there are ways to use the DeepRacer without a connection to AWS.
In addition to the physical vehicle, which can be purchased for hands-on experiences, Amazon also offers the AWS DeepRacer Student League, which can be used separately from the physical model to compete in a global student championship. The aim of this competition is to develop a reward function for the DeepRacer within a month, which uses various parameters to ensure that your own model sets the best time on the current racetrack worldwide. Each participant is given 10 hours of free training time, which can be used to develop a competitive model and become the best in the monthly time trial. Additional hours can also be purchased as required for an extra charge, but this functionality was dispensed with for the sake of fairness and good sportsmanship.
Getting started in the Student League
Due to the size of the team, a total of 30 hours per month was allocated. Participation was in a total of one interval, i.e. a monthly championship.
AWS offers video material for his participants to find the simplest possible entry into the system. Registration as a student is free and possible without specifying a payment method via this link.
A recommendation for writing such methods is to prepare them on a locally installed editor and to copy and paste them into the AWS interface. The latter has problems with proper text formatting and the IDE in general feels less intuitive.
There are three basic algorithms provided by AWS that can be used without further adjustments. With a few hours of training, they already lead to the model completing the time trial without going off track once. These basic algorithms have the following approaches.
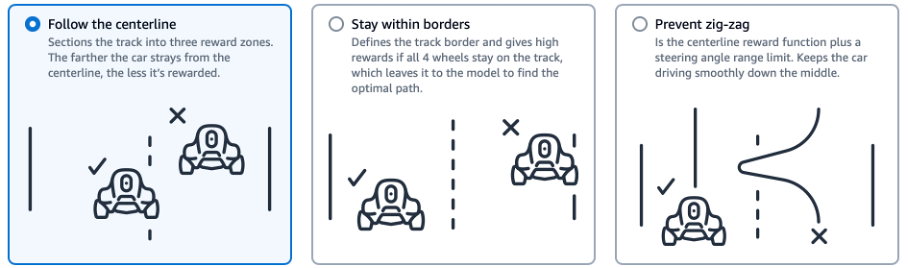
As mentioned, the car can be trained to drive with these reward functions quickly, but proper lap times can not be achieved in this way. Accordingly, the practice hours were used to follow different approaches and implement own reward functions.
The parameters provided by AWS:
{
# flag to indicate if the agent is on the track
"all_wheels_on_track": Boolean,
# agent's x-coordinate in meters
"x": float,
# agent's y-coordinate in meters
"y": float,
# zero-based indices of the two closest objects to the agent's current position of (x, y)
"closest_objects": [int, int],
# indices of the two nearest waypoints
"closest_waypoints": [int, int],
# distance in meters from the track center
"distance_from_center": float,
# Boolean flag to indicate whether the agent has crashed.
"is_crashed": Boolean,
# Flag to indicate if the agent is on the left side to the track center or not.
"is_left_of_center": Boolean,
# Boolean flag to indicate whether the agent has gone off track.
"is_offtrack": Boolean,
# flag to indicate if the agent is driving clockwise (True) or counter clockwise (False).
"is_reversed": Boolean,
# agent's yaw in degrees
"heading": float,
# list of the objects' distances in meters between 0 and track_length in relation to the starting line.
"objects_distance": [float, ],
# list of the objects' headings in degrees between -180 and 180.
"objects_heading": [float, ],
# list of Boolean flags indicating whether elements' objects are left of the center (True) or not (False).
"objects_left_of_center": [Boolean, ],
# list of object locations [(x,y), ...].
"objects_location": [(float, float),],
# list of the objects' speeds in meters per second.
"objects_speed": [float, ],
# percentage of track completed
"progress": float,
# agent's speed in meters per second (m/s)
"speed": float,
# agent's steering angle in degrees
"steering_angle": float,
# number steps completed
"steps": int,
# track length in meters.
"track_length": float,
# width of the track
"track_width": float,
# list of (x,y) as milestones along the track center
"waypoints": [(float, float), ]
}Results
The best placement was achieved by our nicknamed 'RoadrunnerV2' model, which took 569th place among the 3091 participants. For the three laps on the test track, the model needed a time of 02:54.060 without going off track once.
The following reward function was used:
def reward_function(params):
# Read input variables
all_wheels_on_track = params["all_wheels_on_track"]
is_crashed = params["is_crashed"]
speed = params["speed"]
award = 0
if is_crashed or not all_wheels_on_track:
award = 0.0001
else:
award = speed
return awardHere you can see RoadrunnerV2 in action
Final thoughts
DeepRacer gives the user the ability to clone a previous trained model. On the one hand, this feature is useful so that you don't have to start from the beginning with each new model given the time limit of 10 hours, on the other hand it may be necessary to start the model again from scratch, if you have fundamentally adjusted the algorithm. In general, it is good that all participants have the same time limit and that more hours are only available for an additional fee. However, universities with large sponsors have the opportunity to buy more practice time and thus a higher chance of success. More training time should generally be made available and the possibility of being able to buy additional time should be suspended.
In addition, it was not possible for one of our models to reach the model’s advertised maximum speed of up to 4 meters per second, equal to almost 15 km/h. We could not clarify, whether this was an error in our reward functions or AWS limited the speed potential for the student competition.
The DeepRacer is recommended for anyone, who wants to find a playful introduction to reinforcement learning. The visualization of the driving model and the ranking in the student league ensure motivation among the participants with the help of gamification. Thanks to the AWS exclusivity, progress can be made without extensive training or resources of the user, but much of the network and the corresponding 'magic' of the AI behind the system remain hidden, but especially more experienced ones may be interested in these topics.
In order to work independently of AWS, we started developing our own learning environment within Unity, which makes it possible to implement own reward functions to teach cars how to drive on self-created routes. This project is called U-Race (= 'Unity Reinforcement Autonomous Car Environment'). You're welcome to check it out on GitHub or read our corresponding article!