Ein Reinforcement-Learning Agent lernt den Spieleklassiker Snake 🐍

Snake der Spieleklassiker der Millennials, auf jedem alten Nokia Handy vorhanden, begeisterte die kleine Apfel fressende Schlange Jung und Alt. Ziel des Spiel ist es die Schlange durch geschickten Input die zufällig erscheinenden Äpfel fressen zu lassen. Berührt die Schlange die Wand oder ihren eigenen Schwanz ist das Spiel vorbei. Dieses simple aber im späteren Verlauf doch anspruchsvolle Spiel bietet sich aufgrund der steigenden Komplexität gut für den Reinforcement-Learning Ansatz an.
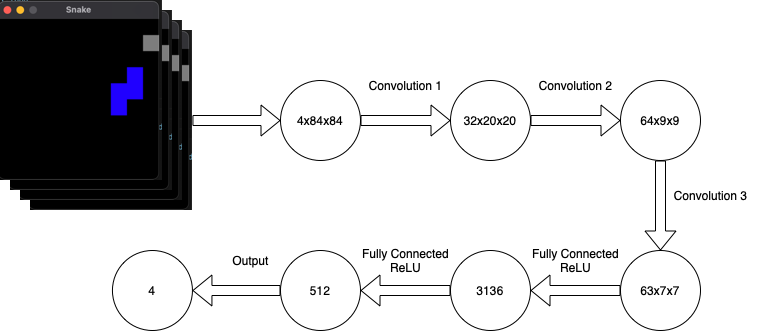
In diesem Projekt wird ein Agent entwickelt, welcher mit Hilfe von Reinforcement-Learning das Spiel Snake spielen lernen soll. Hierzu wurde ein neuronales Netz bestehend aus drei Convolutional-Layern und 2 Dense-Layern entwickelt. Die Architektur des Netzes ist in Abbildung 1 zu sehen. Als Aktivierungsfunktion wurde ReLU verwendet.
Das Snake-Spiel
Das Snake-Spiel selbst wurde mit Hilfe der Bibliothek PyGame realisiert. Es besitzt eine 250 x 250 Pixel große Spieloberfläche. Der Apfel ist 25 x 25 Pixel groß und rot. Die Schlange ist blau, initial 25 x 50 Pixel groß und wächst mit jedem gefressenen Apfel um einen 25 x 25 Pixel Block.
Während eines Spielschrittes kann sich die Schlange in vier unterschiedliche Richtungen bewegen: oben(0), unten(3), links(1), rechts(2). Dies kann der Agent tun, indem er der play_step(self,action) Methode eine entsprechenden Wert übergibt. Anschließend wird mit Hilfe der _move() Methode die Schlange in die entsprechende Richtung bewegt.
def play_step(self, action):
final_move = [0,0,0,0]
final_move[action] = 1
self.frame_iteration += 1
self._move(final_move)
self.snake.insert(0, self.head)Im Anschluss wird überprüft, ob eine Kollision stattgefunden hat, ist dies der Fall, wird folgendes zurück gegeben:
- der negative Reward
- der neue Status des Spiels als Screenshot
- der bool´sche Wert "true", um anzuzeigen, dass das Spiel beendet ist
- die aktuell erreichte Punktzahl
if self.is_collision() or self.frame_iteration > 100*len(self.snake):
game_over = True
reward = -1
return self.get_last_frames(self.screenshot()), reward,
game_over, self.scoreWurde keine Kollision festgestellt, wird falls nötig ein neuer Apfel an einer zufälligen Stelle platziert. Wurde kein Apfel gefressen, wird der letzte Block der Schlange entfernt. Dadurch erscheint es dem Nutzer, als ob sich die Schlange vorwärts bewegt. Die Übergabewerte in diesem Fall unterscheiden sich lediglich in dem bool´schen Wert, da das Spiel nicht beendet wurde.
if self.head == self.food:
self.score += 1
reward = 2
self._place_food()
else:
self.snake.pop()Der Agent erhält "Augen"
Der Agent “sieht” mit Hilfe von Bildern der Spieloberfläche, welche er an das Netz übergibt. Da jedoch aus einem einzelnen Bild keine Informationen zu Bewegungsrichtungen gewinnen lassen, ist es nötig, dass mehrere aufeinander folgende Bilder übergeben werden. Diese werden zunächst in Graustufen und anschließend in Matrizen umgewandelt. Diese können nun an das Netz übergeben werden, welches die neuen Bewegungsrichtungen berechnet. Die Schlange wird sich in Richtung der am höchsten bewerteten Richtung bewegen.
Damit der Agent den Lernprozess schneller bewältigen kann, wurde sich für ein Spielfeld der Größe 250 x 250 Pixel entschieden. Dieses Feld wird mit Hilfe der screenshot() Methode verarbeitet und als Matrix zurückgegeben. Zu dem Verarbeitungsprozess gehören eine Graufärbung, sowie das zuschneiden des Originalbildes auf 84 x 84 Pixel. Durch diesen Prozess kann die zu verarbeitende Datenmenge weiter reduziert werden. In Abbildung 2. ist ein solch bearbeitetes Bild zu sehen. Dabei gilt es zu beachten, dass diese Verarbeitung nicht für jeden Use-Case pauschalisiert werden kann. Die Einfärbung in Graustufen ist nur möglich, da die Farben keine Rolle in Snake spielen. Auch bei dem zuschneiden der Bilder muss gewährleistet werden, dass dem Netz beziehungsweise dem Agent genug Bildinformationen übergeben werden.

def screenshot(self):
data = pygame.image.tostring(self.display, 'RGB')
image = Image.frombytes('RGB', (250, 250), data)
image = image.convert('L')
image = image.resize((84, 84))
matrix = np.asarray(image.getdata(), dtype=np.uint8)
matrix = (matrix - 128)/(128 - 1)
return matrix.reshape(image.size[0], image.size[1])Diese Bildinformationen werden in der get_last_frames(screenshot) Methode zu einem Stapel von vier Matrizen zusammengesetzt und als “State” zurückgegeben. Dabei sorgt eine sogenannte “deque” dafür, dass dieser Stapel auch genau vier Matrizen enthält. Der “State” ist dementsprechend das was das Agent “sieht” und wodurch die folgenden Aktionen berechnet werden können.
def get_last_frames(self, screenshot):
frame = observation
if self._frames is None:
self._frames = deque([frame] * self._num_last_frames)
else:
self._frames.append(frame)
self._frames.popleft()
state = np.asarray(self.frames)
return stateDer Agent übergibt den State an das Neuronale Netz, wodurch die nachfolgenden Aktionen berechnet werden. Der Input des Netzes setzt sich hierbei aus der besagten 4 x 84 x 84 großen Matrix zusammen.
Oh a piece of Candy
Damit der Agent überhaupt lernen kann, ist im Reinforcement-Learning ein sogenannter Reward (Belohnung) notwendig. Simpel dargestellt wird der Agent für eine “gute” Aktion belohnt, er bekommt ein virtuelles Bonbon. Der Reward ist die wichtigste Rückmeldung an den Agenten. Diese Belohnung steuert den gesamten Lernprozess und die zukünftigen Aktionen des Agenten.
Die Folgenden Rewards kann der Agent für seine Aktionen erhalten:
- Findet der Agent den Apfel, so erhält er einen positiven Reward von 2.
- Findet eine Kollision statt (entweder mit der Mauer, oder der Schlange selbst) ist das Spiel vorbei und der Agent erhält einen negativen Reward von -1.
- Ebenso gibt es eine Abbruchbedingung für den Fall, dass längere Zeit kein Apfel gefunden wurde. Dies soll verhindern, dass der Agent eine Strategie wählt, welche die Schlange nur am Rand des Spielfeldes kreisen lässt. In diesem Fall wird das Spiel neu gestartet und ein negativer Reward von -1 an den Agenten übergeben
- Um dem Agenten einen größeren Anreiz zu geben, sich schneller zu einem Apfel zu begeben wurde ein weiterer negativer Reward von -0,02 eingeführt. Dieser Reward wird für jede weitere ausgeführte Aktion an den Agenten übergeben. Dabei gilt es zu beachten, dass der Reward nicht zu klein gewählt wird, da es dem Agenten ansonsten klüger erscheinen könnte, die Anzahl an Aktionen zu verringern, indem er das Spiel durch eine Kollision beendet.
reward = -0.02
game_over = False
if self.is_collision() or self.frame_iteration > 100*len(self.snake):
game_over = True
reward = -1
return self.get_last_frames(self.screenshot()), reward,
game_over, self.score
if self.head == self.food:
self.score += 1
reward = 2
self._place_food()
else:
self.snake.pop()
self._update_ui()
self.clock.tick()
return self.get_last_frames(self.screenshot()), reward, game_over, self.scoreDas Gedächtnis und der Lernprozess des Agenten
Das Training der Netze geschieht mit Hilfe einer deque, in welcher für jeden Schritt die folgenden Daten gespeichert werden:
- die Ausgangsposition
- die aktuell vorgenommene Aktion
- die nachfolge Position
- der erhaltene Reward
Da dies sehr speicherintensiv ist, muss hier auf die zu Verfügung stehenden Ressourcen geachtet werden, da ansonsten ein Overflow oder ein Absturz droht. Aus diesem Grund wurde die Größe in der Implementierung auf 40.000 Einträge festgelegt. Dies lastet eine Grafikkarte mit 10 Gigabyte Speicher gänzlich aus. Ist diese Zahl von Einträgen erreicht, wird bei dem nächsten Eintrag der älteste nach dem "Pop-left" Prinzip gelöscht.
Die Aktionsauswahl während des Lernprozesses wird in Exploration und Exploitation unterteilt. Während des Lernvorganges werden Zufällig 32 dieser Einträge zu einem Batch zusammengefasst und mit den Netzen eine Aktion berechnet. Anhand der errechneten Aktionen werden im Anschluss die beiden Netze trainiert. Dazu werden die Q-values und der Loss berechnet.
def learn(self):
if self.curr_step % self.sync_every == 0:
self.sync_Q_target()
if self.curr_step % self.save_every == 0:
self.save()
if self.curr_step < self.steps_before_learning:
return None, None
if self.curr_step % self.learn_every != 0:
return None, None
# Get Samples from memory
state, next_state, action, reward, done = self.recall()
# Get Estimate Q-value
estimate =self.net(state, model=NetMode.TRAINING)[np.arange(0, self.batch_size), action]
# Get next Q-value for loss
nextQ = self.calc_next_Q(reward, next_state, done)
loss = self.update_Q_training(estimate, nextQ)
return (estimate.mean().item(), loss)Exploration vs Exploitation
Die Schlange beziehungsweise der Agent steht vor einem typischen Dilemma. Soll er seine Strategie weiter beibehalten (Exploitation), oder soll eine gänzlich neue gewählt werden (Exploration), um schneller ans Ziel zu gelangen.
Um dieses Dilemma zu lösen, gibt es verschiedene Methoden, wie beispielsweise das "Epsilon-greedy-Prinzip", welches auch in diesem Ansatz implementiert wurde.
Bei der Aktionsauswahl nach dem "Epsilon-greedy-Prinzip" nutzt der Agent sowohl Exploitation, um sich Vorwissen zunutze zu machen, als auch Exploration, um nach neuen Strategien zu suchen. Das "Epsilon-greedy-Prinzip" wählt die meiste Zeit die Aktion mit der höchsten errechneten Belohnung. Ziel des Prinzips ist es, ein Gleichgewicht zwischen Exploration und Exploitation herzustellen. Zu beginn des Lernprozesses ist der Anteil an zufälligen Aktionen noch sehr hoch, wohingegen die berechneten Aktionen mit steigender Erfahrung des Agenten zunehmen.
def get_action(self, state):
# EXPLORE (Ausführen zufälliger Actionen)
if np.random.rand() < self.exploration_rate:
action_idx = np.random.randint(self.action_dim)
self.random += 1
# EXPLOIT (verwendet Voraussage der KI)
else:
state = torch.FloatTensor(state).cuda() if self.use_cuda
else torch.FloatTensor(state)
state = state.unsqueeze(0)
action_values = self.net(state, model=NetMode.TRAINING)
action_idx = torch.argmax(action_values).item()
self.calc +=1
# verringern der exploration_rate
self.exploration_rate *= self.exploration_rate_decay
self.exploration_rate = max(self.exploration_rate_min, self.exploration_rate)
self.curr_step += 1
return action_idx, self.calc, self.randomDie beiden Gehirnhälften
Da der Ansatz des traditionellen Q-Learning oftmals dazu neigt die Zustand-Aktions paare deutlich zu überschätzen, wurde der Ansatz des Double Q-Learning verfolgt und implementiert.
Für das Double Q-Learning werden zwei Netze initialisiert das Target- sowie das Training-Netz. Während des Lernvorgangs wird das Trainings-Netzwerk verwendet, um eine Aktion vorauszusagen, während das Target-Netzwerk dazu verwendet wird, um diese zu evaluieren.
Hierbei wird bei jedem Training Schritt das Trainings-Netzwerk aktualisiert. Alle 10.000 Schritte kommt es zu einer Synchronisation der beiden Netzwerke: Dabei wird das sogenannte "State-dictionary", welches die Gewichte der Netze enthält, kopiert.
Die Auswahl welches Netz verwendet werden soll, wird durch ein Enum getroffen:
def forward(self, input, model):
if model == NetMode.TRAINING:
return self.trainingNet(input)
elif model == NetMode.TARGET:
return self.targetNet(input) @torch.no_grad()
def calc_next_Q(self, reward, next_state, done):
next_state_Q = self.net(next_state, model=NetMode.TRAINING)
best_action = torch.argmax(next_state_Q, axis=1)
next_Q = self.net(next_state, model=NetMode.TARGET)[np.arange(0, self.batch_size), best_action]
return (reward + (1 - done.float()) * self.gamma * next_Q).float() def update_Q_training(self, current_Q, next_Q) :
loss = self.loss_function(current_Q, next_Q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item() def sync_Q_target(self):
self.net.targetNet.load_state_dict(self.net.trainingNet.state_dict())Schlusswort
Abschließend gilt es zu sagen, dass in diesem Projekt ein Agent entwickelt wurde, welcher schon nach 24 Stunden Training in der Lage war, eine maximale Punktanzahl von 26 zu erreichen.
Als Training Hardware wurde eine Google-Cloud-VM Instanz verwendet:
- n1-highmem-2
- Tesla K 80 GPU
Der komplette Code ist in diesem Github-Repository zu finden.