KI-ndervideos: Vollautomatische Erstellung von Kinderlerninhalten mittels KI-Pipelines

Einleitung
Die Idee für dieses Projekt entstand aus einem persönlichen Bedürfnis: Wie kann man schnell und unkompliziert Lernvideos für ein Kind erstellen, das gerne Englisch lernen würde?
Die Erstellung von qualitativ hochwertigem Lernmaterial ist extrem zeit- und ressourcenintensiv. Professionelle Videos erfordern Kenntnisse in Grafikdesign, Videobearbeitung, Vertonung und Musikproduktion. Daher war das Ziel des Projekts die Erstellung eines Tools, das diesen Prozess automatisiert. Der Nutzer gibt lediglich ein Thema vor und verschiedene, spezialisierte KI-Tools generieren daraufhin selbstständig das komplette Lernvideo.
YouTube Playlist mit den Videos
Vom Thema zum fertigen Video:
Der Start des Programms passiert über einen Aufruf in der Kommandozeile. Der Nutzer initiiert hier den Vorgang, indem er einfach das gewünschte Thema, zu dem die Videos erstellt werden sollen, mitgibt. Die folgende Abbildung zeigt den Ablauf im Überblick.
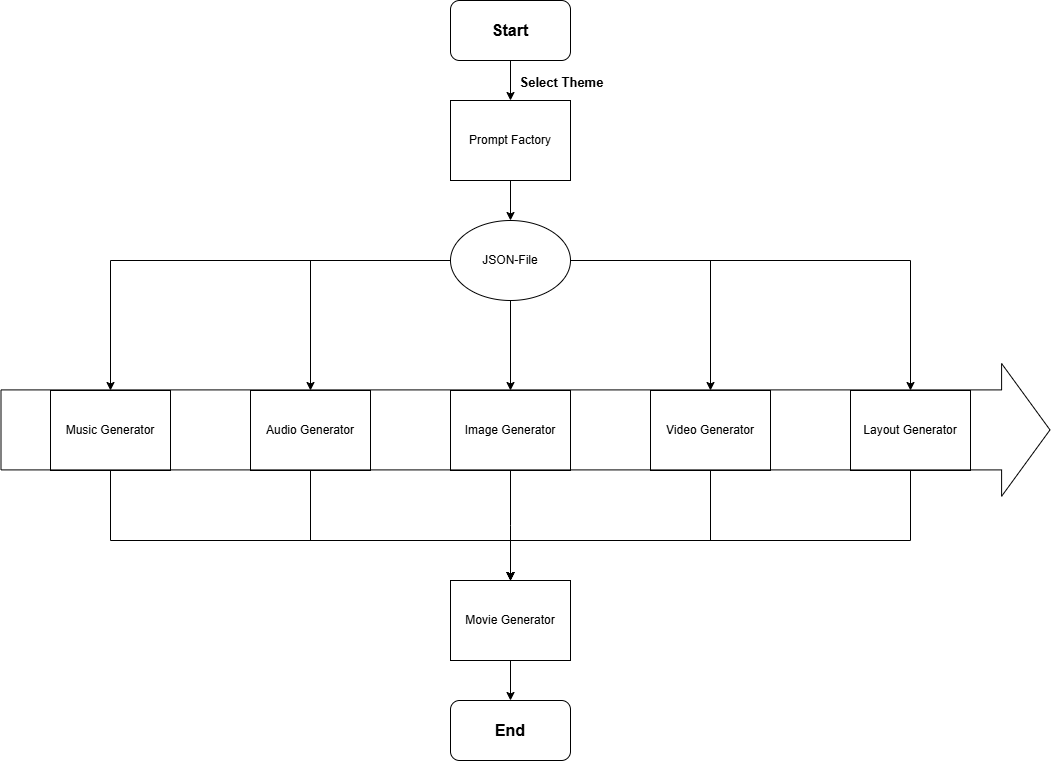
Schritt 1: Die Prompt Factory:
Die Prompt Factory nutzt die mitgegebene Kategorie und erstellt mithilfe eines LLMs den thematischen Inhalt des Videos. Die erstellte JSON-Datei dient als zentraler Bauplan und wird im nächsten Schritt zur Asset-Generierung verwendet. Sie enthält unter anderem die Vokabeln und die Übersetzungen sowie die verschiedenen Intro und Outro-Sätze.
Schritt 2: Die Asset-Generierung:
Die JSON-Datei wird an spezialisierte Generatoren weitergereicht, die jeweils einen bestimmten Baustein des Videos generieren. Der Music Generator komponiert eine passende Hintergrundmelodie, der Audio Generator wandelt die Vokablen und Texte in gesprochene Sprache um und der Video Generator erstellt mit Hilfe der vom Image Generator generierten Bilder die passenden Videos. Der Layout Generator definiert die visuelle Struktur des Videos und gibt vor, an welcher Stelle was eingebettet werden soll.
Schritt 3: Das Zusammenfügen der einzelnen Elemente:
Im letzten Schritt kommen alle Einzelteile im MovieGenerator zusammen. Die Videos, die Musik, die Sprachaufnahmen und die Layout-Vorgaben werden zu einem Lernvideo zusammengefügt und als MP4-Datei ausgegeben.
Umsetzung:
Im folgenden werden die einzelnen Teilschritte näher erläutert und ihre Funktionsweise und aufgetretenen Probleme sowie deren Lösungen beschrieben.
Prompt Factory:
Um ein Video vollständig durch KI generieren zu können, benötigt es erst die folgenden Komponenten:
- Eine Wortliste mit 10 Subjekten pro Thema
- Die deutsche und englische Übersetzung
- Ein Prompt für Bild- und Videogenerierung
- Ein Skript für das TTS-Modell
- Intro und Outro zum Video
- Intro und Outro zum Quiz
- Vorstellung des Subjekts
- Abfrage des Subjekts für das Quiz
- Antwort auf die Abfrage im Quiz
Die einfachste Lösung zur Sammlung der geforderten Komponenten ist eine JSON-Datei, in der alle Komponenten gesammelt werden und welche dann an die jeweiligen KI-Modelle verteilt wird. Die folgende Abbildung zeigt einen Ausschnitt aus der JSON-Datei.
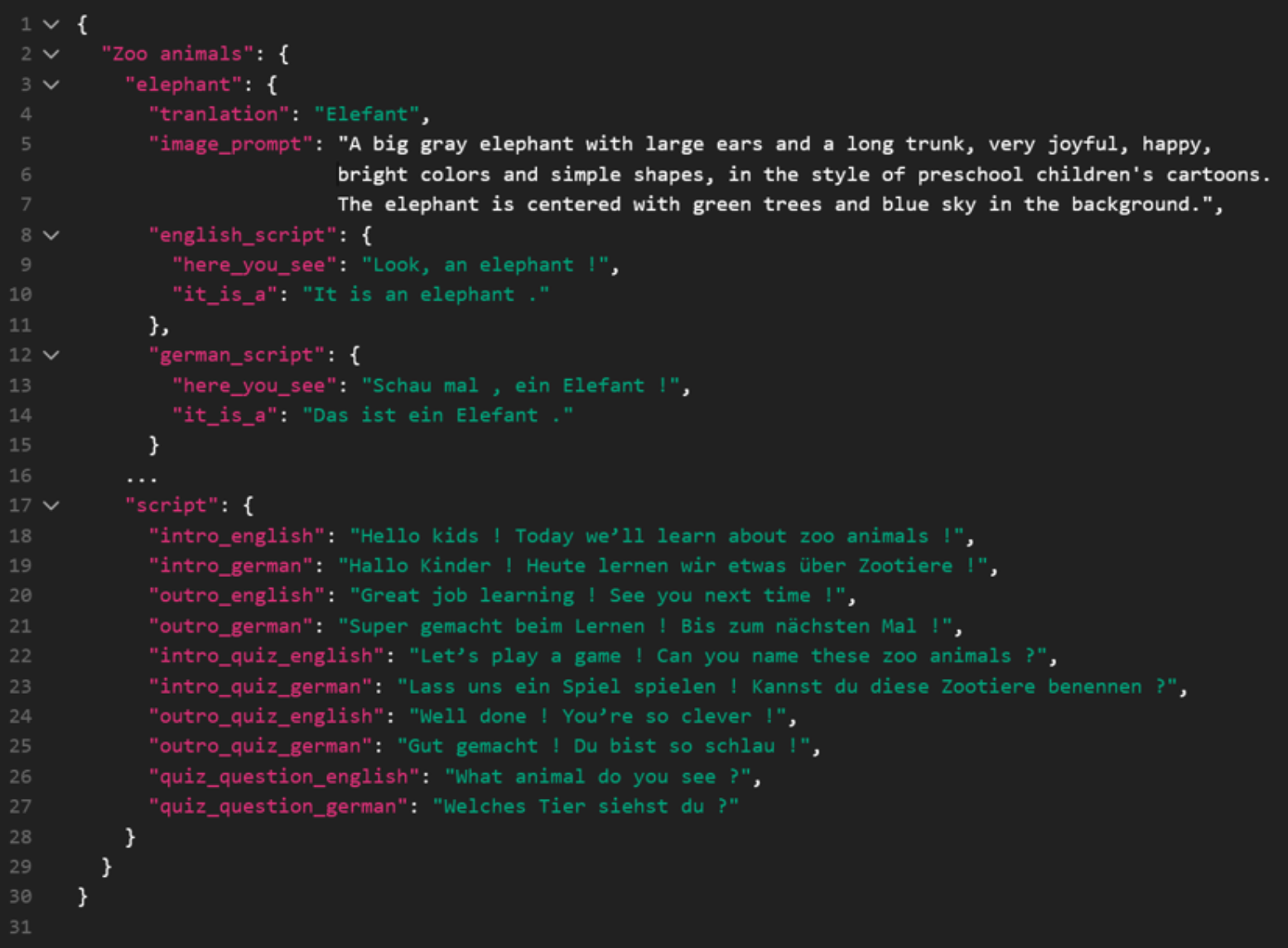
Damit Wortpaare, Skripte und Prompts dynamisch passend zu jedem Thema und jedem Subjekt erstellt werden, wurde ein Large Language Modell verwendet, welches zu jedem Thema eine JSON-Datei zurückgibt.
Hierfür wird ein großer feststehender Prompt verwendet. Der Prompt ist unterteilt in vier Aufgaben:
- Erstelle 10 Wortpaare
a. Benutze nur simple Worte
b. Englische und deutsche Übersetzung - Erstelle einen Prompt zur Bildgenerierung
a. Der Stil sollte fröhlich sein, mit hellen Farben und einfachen Formen. Passend zu Cartoons für Kindergartenkinder.
b. Das Subjekt sollte vollständig auf dem Bild zu sehen sein.
c. Beschreibe keine Bewegung. - Video-Skript zum Vokabeln lernen
a. 1. Satz zum Vorstellen des Subjekts
b. 2. Satz zur Antwort auf die Abfrage - Skript für das Vollständige Video
a. Intro: Freundliche Begrüßung
b. Outro: Ermutigender Abschluss
c. Quiz Intro
d. Quiz Outro
Zu den Skripten und dem Prompt wird jeweils ein Beispiel mitgeliefert, an dem sich das LLM orientieren kann. Am Schluss des Prompts wird die Struktur der JSON-Datei vorgegeben, die das LLM zurückgeben soll.
Der Music Generator:
Für eine ansprechende Lernerfahrung ist eine passende musikalische Untermalung unerlässlich. Ein Lernvideo ohne sie könnte schnell als langweilig empfunden werden und sich unnatürlich anfühlen. Der Music Generator hat daher die Aufgabe, für jedes Video eine zum Thema passende Hintergrundmusik zu komponieren. Ziel ist es, eine freundliche und motivierende Atmosphäre zu schaffen, ohne vom Lerninhalt abzulenken. Dazu wurde das musicgen-medium Modell von Facebook verwendet. Es wandelt einen Prompt in Musik um und erlaubt die Spezifizierung verschiedener Instrumente und des Tempos. Dies ermöglicht uns zu garantieren, dass die Musik für ein Kinderlernvideo geeignet ist und das Video musikalisch untermalt ohne sich ablenkend in den Vordergrund zu drängen. Die folgende Abbildung zeigt einen Ausschnitt des Codes.
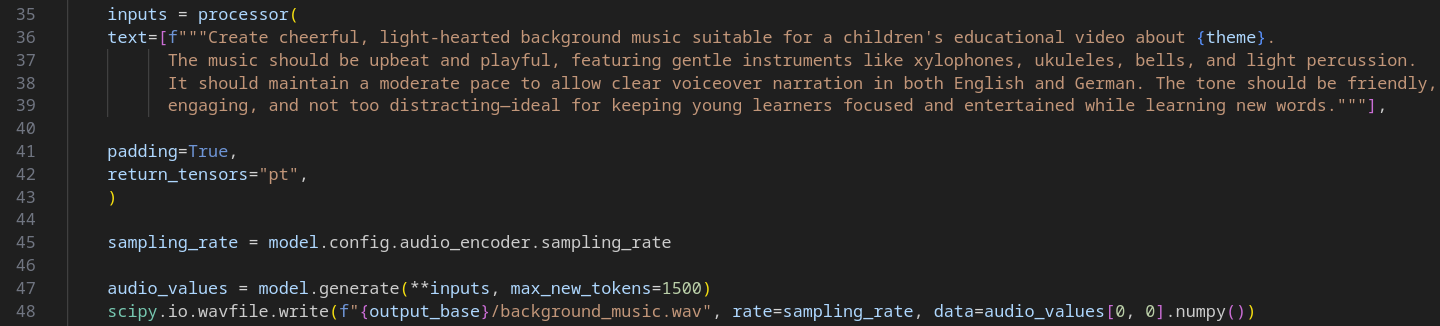
Nachdem der Processor den Prompt verarbeitet hat, wird dem Modell der Auftrag erteilt daruas Musik zu generieren. Max_new_tokens beschreibt die maximale Anzahl der neuen Tokens, welche hier auf das Maximum gesetzt ist. Dies entspricht 30 Sekunden. Sollte mehr Musik benötigt werden, so wird diese geloopt.
Der Audio Generator
Der Audio Generator hat die Aufgabe, dem Lernvideo eine Stimme zu geben. Er ist dafür verantwortlich, alle textlichen Inhalte aus der JSON-Datei – von der Begrüßung über die Vokabeln bis hin zu den Quizfragen – in klar verständliche, gesprochene Sprache umzuwandeln. Da die Videos zweisprachig konzipiert sind, muss eine qualitativ hochwertige Vertonung sowohl auf Englisch als auch auf Deutsch sichergestellt werden. Ursprünglich war geplant, für beide Sprachen ein einziges, leistungsstarkes multilinguales Modell zu verwenden. In der Praxis zeigte sich jedoch, dass die deutsche Aussprache dieses Modells nicht die gewünschte Klarheit und Natürlichkeit erreichte. Außerdem kann es pädagogisch sinnvoll sein, die beiden Sprachen von unterschiedlichen Stimmen unterschiedlicher Geschlechter vertonen zu lassen. Dies führt zu einer deutlichen Trennung der beiden Sprachen im Kopf des Hörers. Aus diesen Gründen wurde ein hybrider Ansatz gewählt:
Für die Für die englische Vertonung wird das xtts_v2 Modell mit der freundlichen Sprecherstimme "Claribel Dervla" genutzt. Für die deutsche Vertonung wird auf das spezialisierte Modell thorsten/vits zurückgegriffen, welches auf die deutsche Sprache optimiert ist. Dies zeigt die folgende Abbildung.

Im weiteren Teil des Skripts wird über die JSON-Datei iteriert und es werden die Tondateien als WAV-Dateien abgelegt.
Der Image Generator:
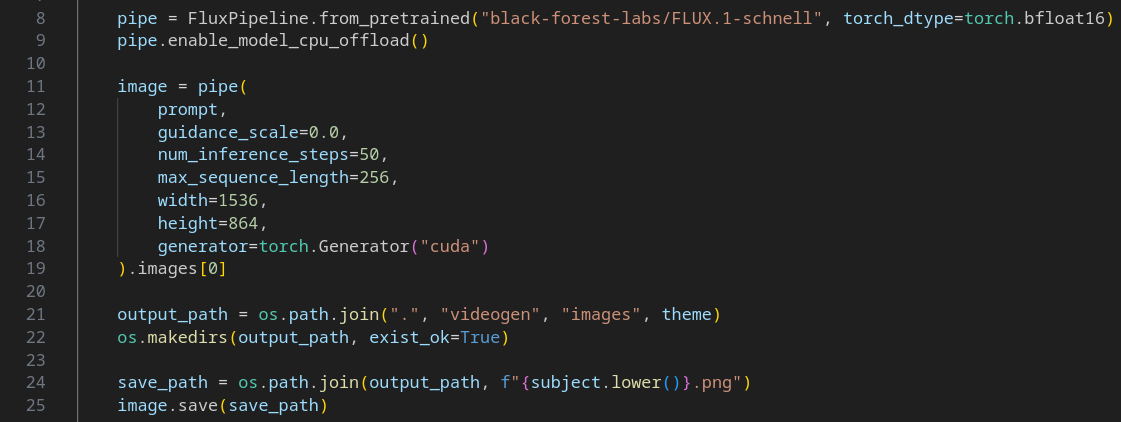
Der Image Generator ist für die Erstellung des visuellen Kerns der Lernvideos verantwortlich. Seine Aufgabe ist es, für jede Vokabel aus der JSON-Datei ein einzigartiges und stilistisch passendes Bild zu generieren. Da Text to Video in früheren Versionen Schwierigkeiten bereitete, wurde die Bildgenerierung als Zwischenschritt eingefügt. Das erstellte Bild wird im Video Generator animiert und zum Leben erweckt. Zur Generierung des Image wird das Modell FLUX.1 verwendet. Im Prompt wird wie in vorherigen Generatoren sichergestellt, dass das Bild thematisch zu einem Kinderlernvideo passt. Die Bilder werden dazu in einem Cartoonstil erstellt. Der folgende Codeausschnitt zeigt die entsprechenden Aufrufe:
Der Video Generator:
Die Aufgabe des Video Generators ist es, die im Image Generator erstellten Bilder zum Leben zu erwecken. Statt Text-to-Video wird hier der Ansatz Image-to-Video verwendet.
Zur Generierung der einzelnen Videos aus wurde das LTX-Video Modell verwendet. Entwickelt wird das Modell von Lightbricks und kommt in einer 2B- und einer 13B-Größe. Zusätzlich werden drei Varianten angeboten, welche sich in den VRAM Anforderungen und daraus folgend der Geschwindigkeit und Genauigkeit unterscheiden. Das Modell kann durch die Diffusers Python-Bibliothek einfach verwendet werden.
Die Generierung eines Videos ist in drei Schritte unterteilt:
- Zuerst wird ein Video aus dem Bild mit einer verringerten Auflösung erzeugt. Das hat den Vorteil, dass zum einen die VRAM-Nutzung verringert wird und zum anderen wird dadurch die Inferenzzeit verringert. Des Weiteren arbeiten Modelle wie LTX zunächst in einem komprimierten latenten Raum, wo sie Struktur, Bewegung und Kohärenz lernen. Diese Muster sind bei niedrigeren Auflösungen leichter kohärent zu erzeugen.
- Im zweiten Schritt wird das Video durch einen Upsampler wieder auf die ursprüngliche Auflösung zurückgebracht. Dadurch werden Details und Schärfe verbessert.
- Zum Schluss wird das Video noch einmal mit einem Denoiser verarbeitet, wodurch Rauschen und Artefakte reduziert werden und somit die Bildqualität verbessert wird.
Am Ende der Pipeline erhält man ein Video, auf dem sich das Subjekt des ursprünglichen Bildes bewegt.
Der Layout Generator:
Nachdem alle KI-generierten Assets erzeugt wurden, tritt der Layout Generator in Aktion. Im Gegensatz zu den vorherigen Komponenten ist dies kein KI-Modell, sondern ein klassisches Python-Skript, das mit der Bildbearbeitungsbibliothek Pillow arbeitet. Seine Aufgabe ist es, als " für jede Szene des Videos ein passendes Layout zu erstellen. Er kombiniert vorgefertigte Hintergrundbilder mit den Texten aus der JSON-Datei und schafft so die visuelle Grundlage für den finalen Schnitt. Es ist auch möglich, das Hintergrundbild zufällig auswählen zu lassen. Anschließend analysiert eine Funktion die dominante Farbe dieses Bildes und verwendet sie als füllfarbe für die Textboxen. Dies sorgt für visuelle Abwechslung und stellt gleichzeitig sicher, dass sich die Elemente harmonisch in das Gesamtbild einfügen.
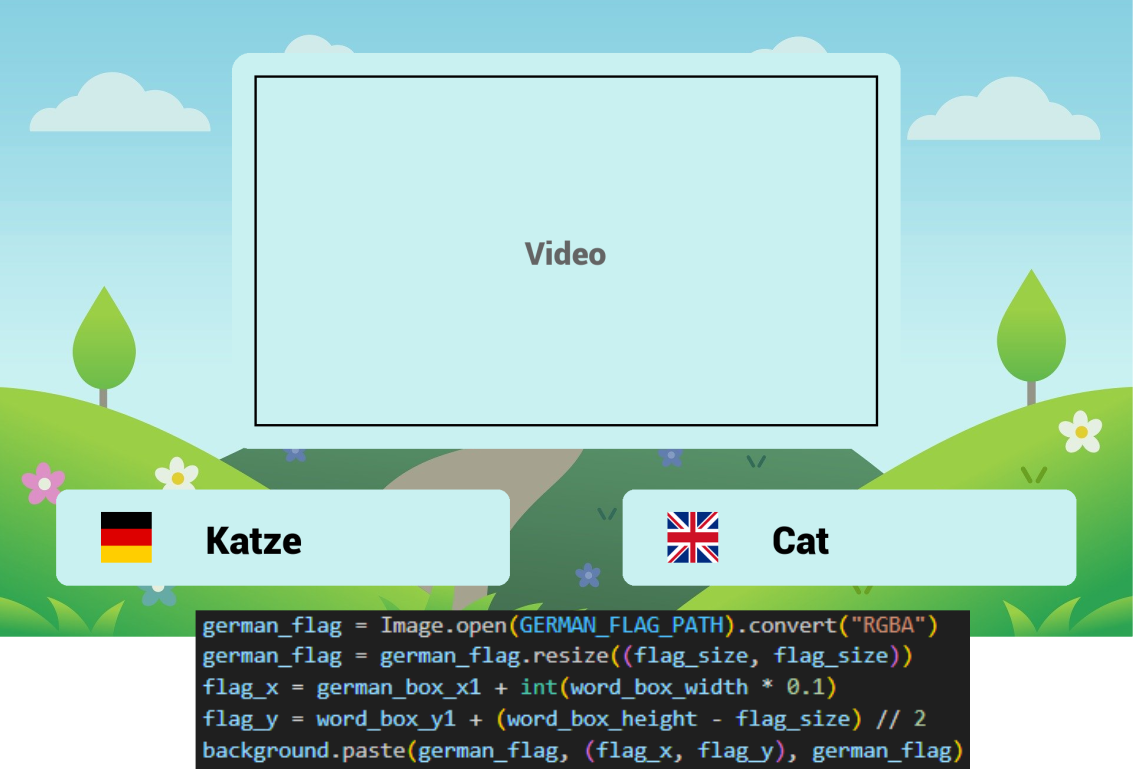
Der Movie Generator:
Der Movie Generator ist der letzte und entscheidende Schritt in der Pipeline. Er fungiert als virtueller Cutter und setzt alle zuvor erstellten Einzelteile zu einem fertigen Lernvideo zusammen. Dafür verwendet er die Python-Bibliothek MoviePy.
Das Skript lädt in einer festgelegten Reihenfolge (Intro, Lektionen, Quiz, Outro) die entsprechenden Layout-Bilder. Für jede Szene führt es die folgenden Schritte aus:
- Platzierung der Medien: Das animierte Video oder das Quizbild wird in den vordefinierten Platzhalter des Layouts eingefügt.
- Synchronisation mit Audio: Die passende Tonspur (z. B. die Vorstellung des Vokabels oder die Quizfrage) wird geladen und die Dauer der Szene exakt an die Länge der Audiodatei angepasst.
- Hinzufügen von Musik: Nachdem alle Szenen zu einem Gesamtclip kombiniert wurden, wird die vom MusicGenerator erstellte Hintergrundmusik unterlegt und in der Lautstärke angepasst.
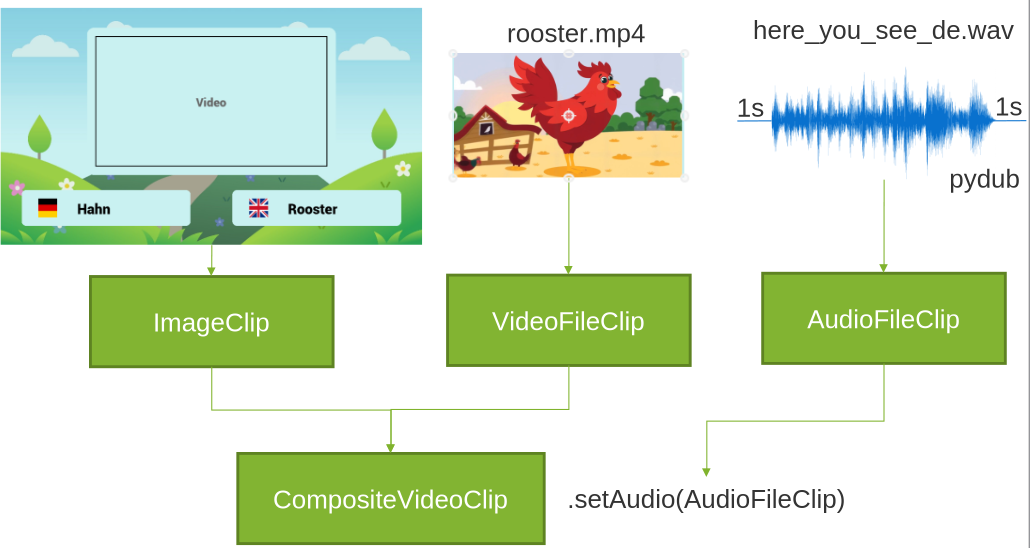
Nachdem alle Szenen erstellt und aneinandergereiht wurden, exportiert der MovieGenerator das Endergebnis als finale MP4-Datei. Damit ist der vollautomatisierte Prozess von der einfachen Themeneingabe bis zum fertigen Lernvideo abgeschlossen.
Fazit und Ausblick:
Das Projekt “KI-ndervideos” zeigt, dass die vollautomatisierte Erstellung von rudimentären, zweisprachigen Lerninhalten heute machbar ist. Es wurde erfolgreich ein Tool entwickelt, das aus einer einzigen thematischen Vorgabe eines Nutzers ein vollständiges Lernvideo generiert.
Durch die Verkettung spezialisierter KI-Modelle für Text, Audio, Musik, Bild und Video wurde eine komplette Produktionskette nachgebildet. Die größte Herausforderung lag in der Konzeption der Prompt Factory und dem Zusammenfügen der einzelnen Assets. Diese Factory agiert als zentrales Gehirn, das aus einem einfachen Wort ein detailliertes Drehbuch für alle nachfolgenden Prozesse erstellt. Das präzise Synchronisieren der vielen unterschiedlichen Assets – von Videoclips über diverse Tonspuren bis hin zur Musik, die alle potenziell unterschiedliche Längen aufweisen – erforderte eine komplexe Logik im Movie Generator. Die im Projekt gemachten Erfahrungen zeigten aber auch typische Hürden auf, wie die Notwendigkeit, für eine qualitativ hochwertige Vertonung auf einen hybriden Ansatz mit zwei verschiedenen Sprachmodellen zurückzugreifen, oder den hohen Bedarf an Rechenleistung, insbesondere bei der Video-Generierung.
Die Lösung bietet außerdem großes Potential für zukünftige Erweiterungen. So könnte es in Zukunft die Möglichkeit geben, die Sprachen frei zu wählen und sich nicht auf Deutsch und Englisch zu beschränken. Es gibt außerdem Optimierungsoptionen bei der Image- und Video-Generierung, da es dort zahlreiche verschiedene Modelle gibt und nicht alle im Rahmen des Projekts getestet werden konnten. Insgesamt legt das Projekt ein starkes Fundament und zeigt, wie generative KI dazu genutzt werden kann, um personalisierte Lerninhalte zugänglicher und einfacher zu erstellen.