Mastering Othello: Unleashing the Power of Double Deep Q-Learning
Our Motivation
Why did we choose Q-Learning?
This team project was part of the Deep Learning SS23 course under the guidance of Professor Beggel. The main objective was to create an AI agent that could kick butt at the game of Othello. Have you heard of Othello? It is a strategic board game for two players, played on an 8×8 uncheckered board (check out https://en.wikipedia.org/wiki/Reversi for more info about the game itself).
When our Deep Learning course started, we had a phase where we set up the gaming platform stuff. Meanwhile, some teams jumped right into coding their agents. One team went for the Monte Carlo Tree Search (MCTS) and the other team started training a Convolutional Neural Network (CNN) using a huge dataset of past Othello games.
At this point, we decided to go with Q-Learning. It's an online algorithm, so we didn't need a massive dataset. Q-Learning is a well-known reinforcement learning algorithm that's used a lot. We had heard about it before in the uni and at work, and now it was our chance to roll up our sleeves and implement it ourselves.
Q-Learning
What is this Q-Learning method we use?
Q-learning is a reinforcement learning algorithm that helps an agent learn optimal actions to maximize its rewards in an environment. It is part of the temporal-difference (TD) learning family of algorithms that combines Monte Carlo methods with Dynamic Programming methods.
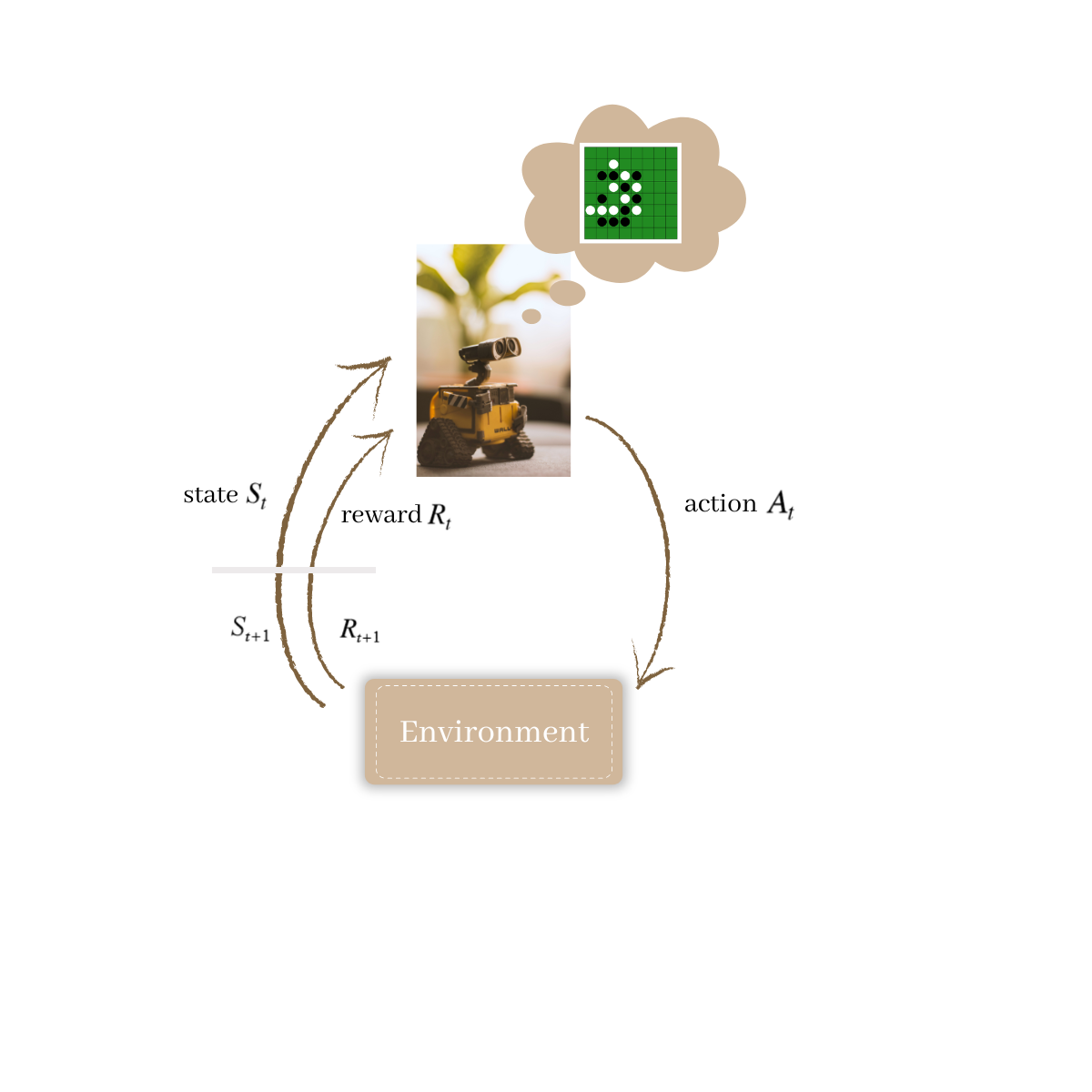
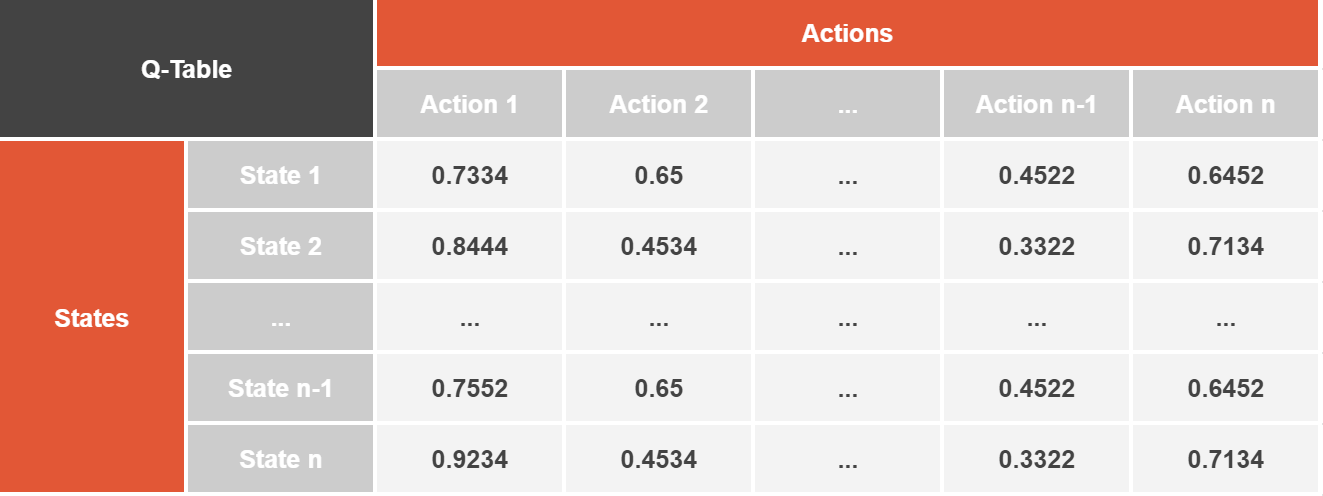
The principle of the reinforcement learning
Robot picture source: https://www.pexels.com/de-de/foto/wall-e-spielzeug-auf-beige-pad-2103864/
Performing Q-Learning is technically like teaching a smart agent to make the decisions when playing a game (Othello in our case) against an opponent. It is an online learning algorithm, meaning that the agent learns as the new data becomes available (during him playing the game).
The agent starts with exploring the game by making random moves. At the end of each game, depending on its outcome, he receives a reward (1 for winning the game, -1 for losing the game, and 0.5 for making it a tie). The goal is to learn how to make the best moves to win the game.
To accomplish this, the classical Q-learning algorithm provides our agent with a memory known as a Q-table, where we store a value for each combination of state and action (https://rubikscode.net/2021/07/13/deep-q-learning-with-python-and-tensorflow-2-0/). For example, a state could be the current configuration of the game board, and an action could be placing a piece in a particular position. The Q-table has a size corresponding to the number of states multiplied by the number of actions.
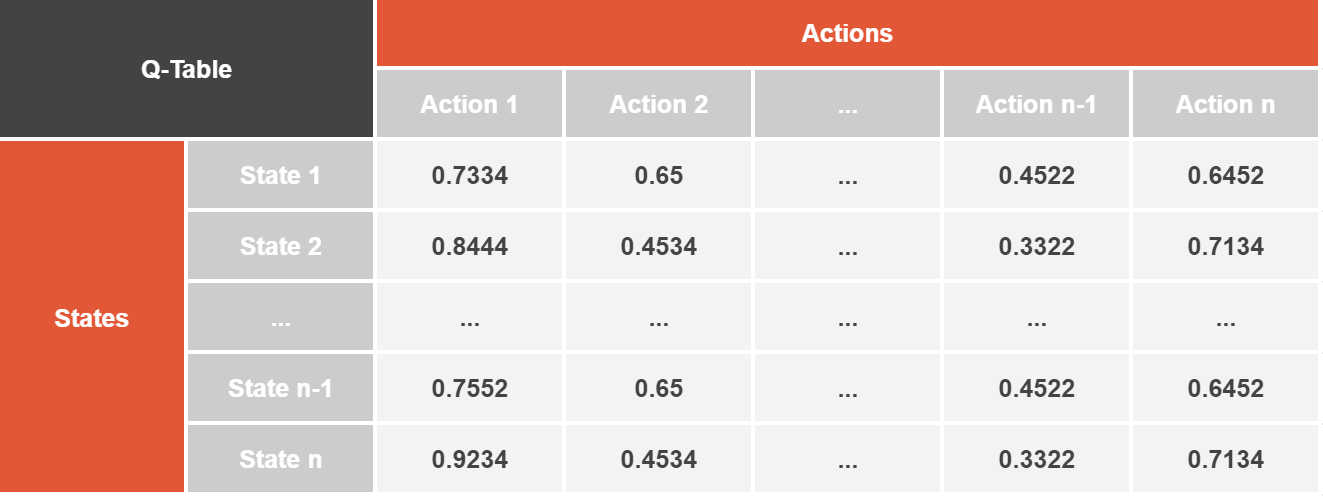
Q-table example structure
Source: https://rubikscode.net/wp-content/uploads/2021/07/qlearningtable.png
{kind=link}
Initially, the Q-table is empty, and the agent explores the game by making random moves. As it plays, it updates the Q-values in the Q-table using a formula that considers the rewards received and the estimated future rewards (https://www.novatec-gmbh.de/en/blog/introduction-to-q-learning/):
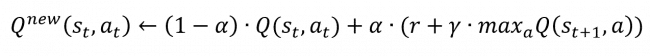
Source: https://www.novatec-gmbh.de/wp-content/uploads/qfunction-650x56.png
{kind=link}
The formula seems complex, so let’s quickly explain it:
- the new Q-values of the state-action pair consists of 2 parts;
- the first part represents the the old Q-value;
- the second part is the sum of the reward r we got by taking action at at state st and the discounted (γ is the discounter factor) estimate of optimal future reward;
- the parameter α is the learning rate and determines the proportion of importance of these 2 parts (the more the α, the more we value the prognose over the value at the current state).
Through trial and error, the agent learns what moves lead to higher rewards, not only at the current step, but also in the future. It gradually updates the Q-values in the Q-table to reflect this knowledge. Over time, the agent becomes smarter and starts making better moves, eventually becoming a formidable opponent (at least it is what we are as developers aiming for).
Strengthening the potential of Q-Learning with Deep-Learning application
Now, let's talk about DQN and DDQN:
DQN, or Deep Q-Network, is an extension of Q-learning that uses neural networks to estimate the Q-values. Instead of a Q-table, the agent has a deep neural network under the hood that takes the game state as input and outputs a vector of Q-values for each possible action. DQN leverages the power of neural networks to handle complex environments with large state spaces (and othello definitely falls under this category!).
It also includes some important features, such as experience replay (instead of immediately using the observed experiences to update the neural network, the agent stores these experiences in a replay buffer or memory). (Hasselt et al., 2015)
The problem with the Q-learning algorithm is that it is known to sometimes overestimate state-action values because it always takes maximum from the estimates and introduces this way a positive bias (Hasselt, 2010). To prevent that, the idea of decoupling the action selection from state-action pair evaluation is implemented in Double Q-Learning (Hasselt et al., 2015).
DDQN, or Double DQN, is a variation of DQN that addresses the problem of overestimation of Q-values. Important ingredients of the DDQN are 2 identical neural network models – policy and target networks. The latter is periodically updated to match the parameters of the first one. In traditional DQN, a single neural network is used for both action selection and Q-value estimation, whereas in DDQN the target network estimates the Q-value.
Having all this knowledge, we implemented a Double DQN method for our agent.
This is our implementation
Code Structure Overview
This diagram shows the implemented components and their relations.
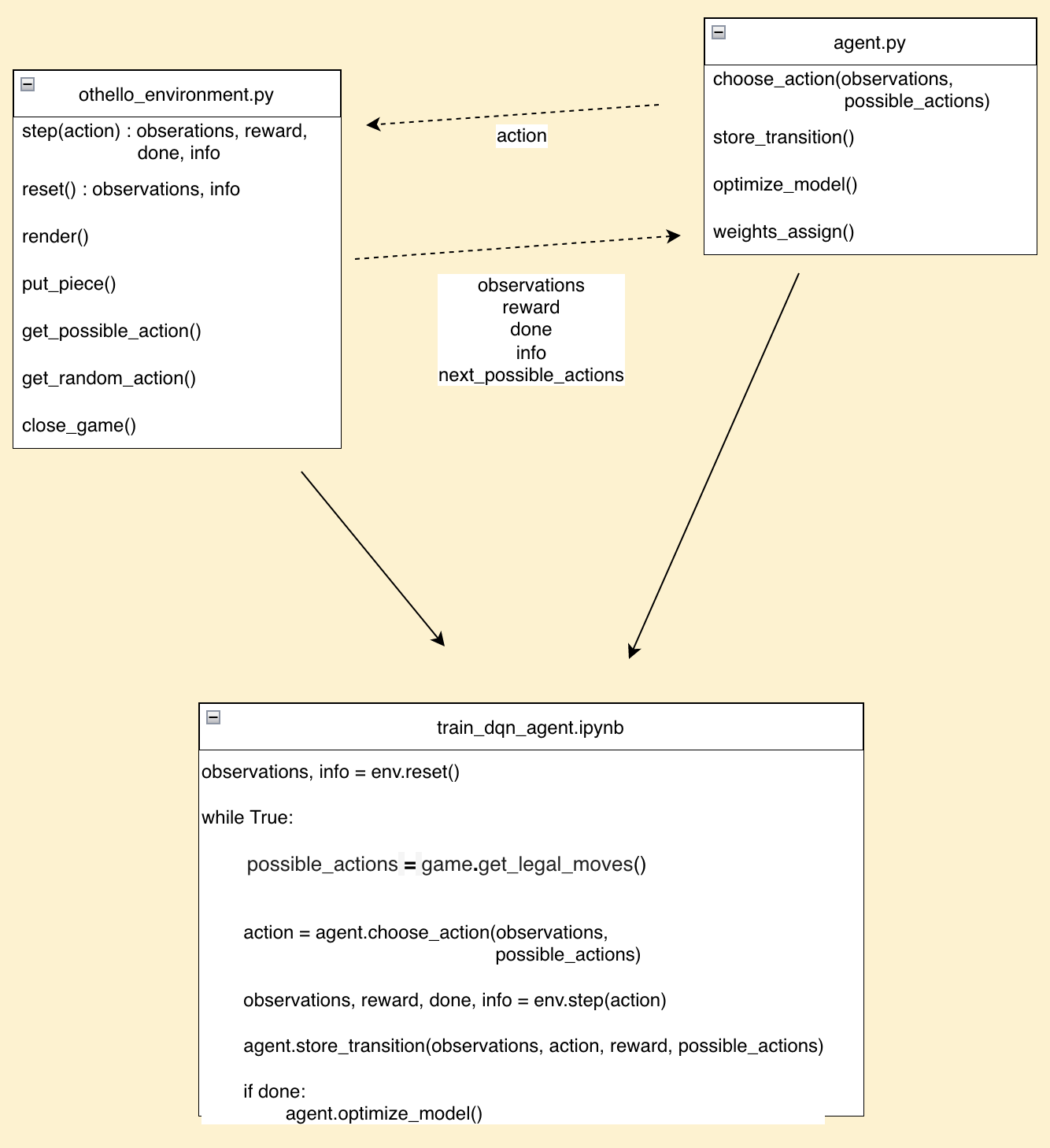
How did we change the original Othello code?
There is an Othello Environment that provides all the code for playing the board game. The original code for this can be found in this repository: https://github.com/SiyanH/othello-game.
What modifications have we made?
- We changed the integer values representing the occupation of the game squares from 0, 1, 2 to -1, 0, 1. Because we want to use these values as input for our network.
- We introduced an info dictionary that includes the current player, the number of white and black stones on the board, the winner, and the next possible actions.
- We renamed make_move() to step() and implemented a right way to finish the game.
- We have also made minor adjustments, which are not worth elaborating on
Our trainingsloop in train_dqn_agent.py
This is a code snippet from our main script train_dqn_agent.py. We also implemented this in a jupyter notebook:
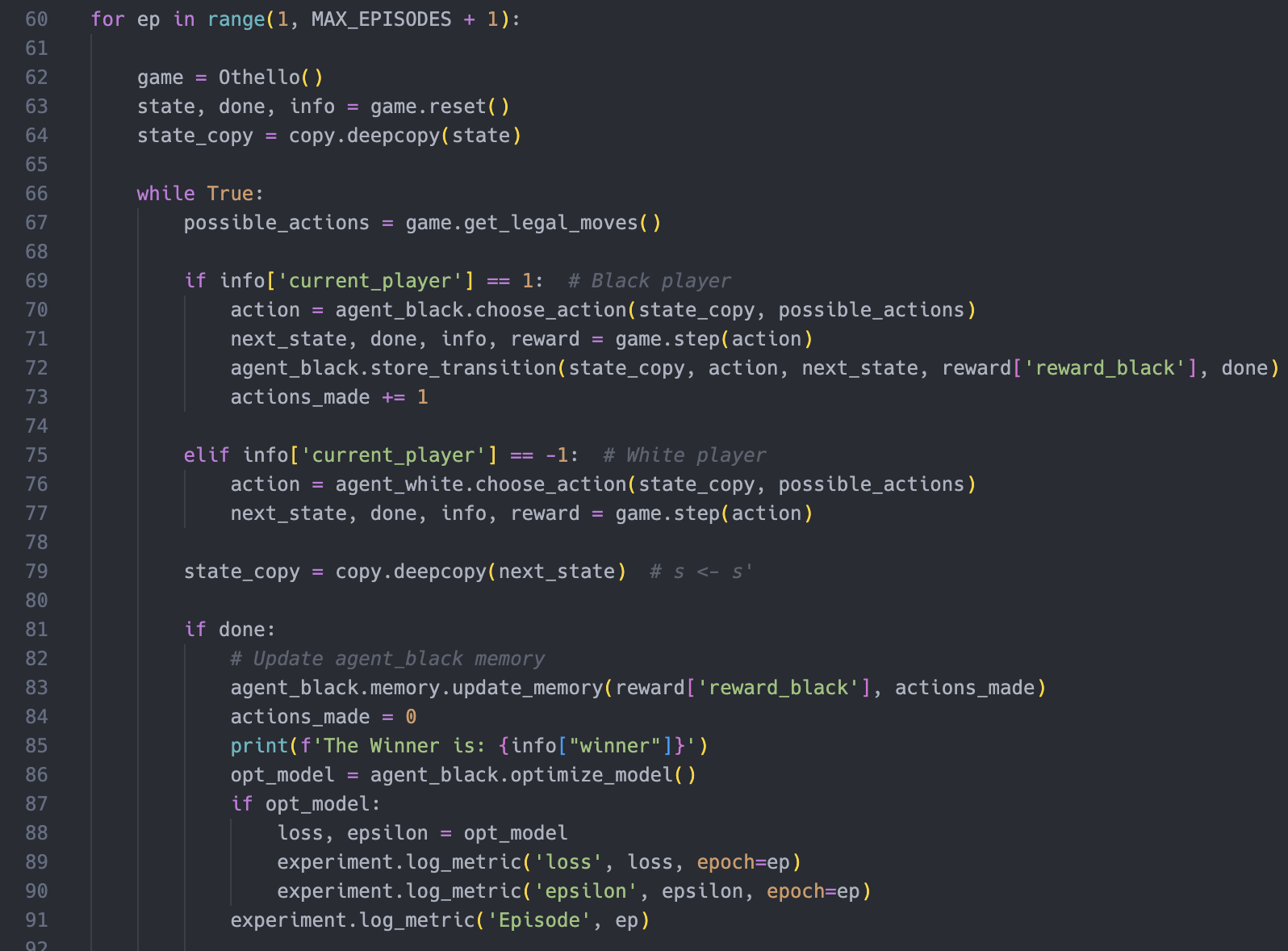
This snippet trains a DQN agent representing the black player to play Othello. It runs multiple episodes of the game. The white player is an older version of the black player which is updated every 2000 episodes.
In each episode, the game is reseted, and the agents make moves until the game is over. The agent's actions are chosen based on the current game state and legal moves available.
After each move, the agent's transition (consisting of the current state, action, next state, reward, and whether the game is done) is stored.
Once the game ends, the agent's memory is updated with the rewards obtained and the number of actions made. This means if the black agent wins the game within 30 moves, the memory is updated afterwards, so that all 30 moves have the reward 1.
After that, the winner is printed, and the agent's model is optimised based on the stored transitions.
The process is repeated for the specified number of episodes, and relevant metrics such as loss and epsilon are logged during training via CometML (see following section). The model with the best winning rate will be saved.
DQN Agent
This is a snippet of our optimize_model() function from DQN_Agent.py.
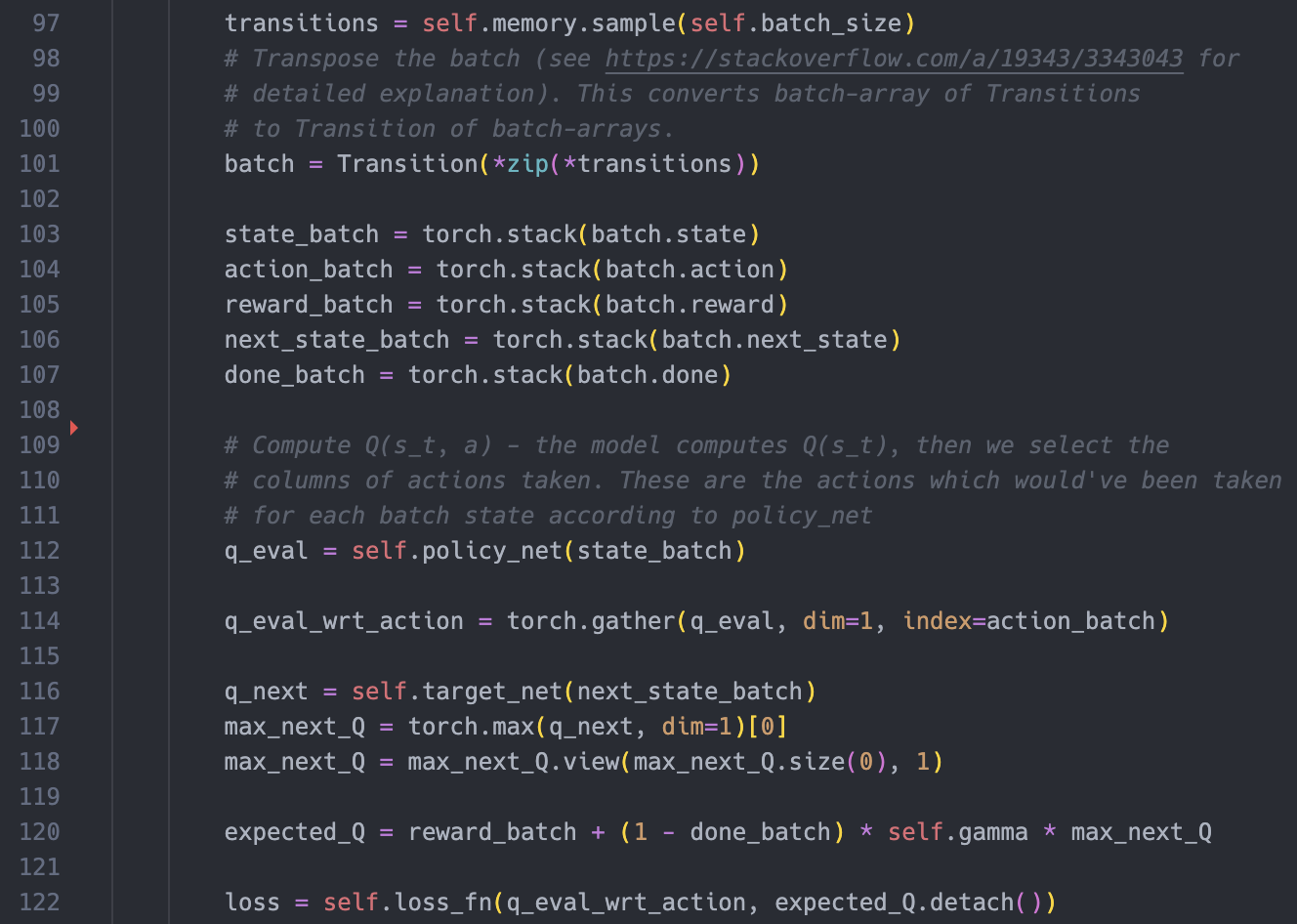
This code segment processes a batch of transitions obtained from the agent's memory to compute the loss for training the model.
First, the method samples a batch of transitions by calling the sample() method on the agent's memory, using the specified batch size. The batch is then transposed to convert it from a batch-array of transitions to a transition of batch-arrays. This is done to make the subsequent computations more efficient.
The individual components of the transition (state, action, reward, next state, done flag) are extracted from the transposed batch using the zip() and * operators, and assigned to their respective variables. Each component of the transition is then stacked using the torch.stack() function to create tensors representing the states, actions, rewards, next states, and done flags of the batch.
The Q-values of the current state-action pairs (q_eval) are computed by passing the state batch through the policy network.
The Q-values corresponding to the selected actions are extracted using the torch.gather() function, specifying the appropriate dimensions and indices.
The Q-values of the next state (q_next) are obtained by passing the next state batch through the target network. The maximum Q-value for each next state is selected using the torch.max() function, and reshaped accordingly.
The expected Q-values (expected_Q) are calculated using the Bellman equation, incorporating the immediate reward, the discount factor (gamma), and the maximum Q-values of the next state. The calculation is performed element-wise.
The loss between the predicted Q-values (q_eval_wrt_action) and the expected Q-values is computed using a specified loss function (loss_fn), with the expected Q-values detached from the computation graph to prevent gradients from flowing back.
Manage your experiments with CometML
CometML is a platform for tracking and managing machine learning experiments. It provides tools for logging and visualising experiment metrics, tracking code versions, and collaborating with team members. CometML allows you to easily log and compare experiment results, track hyperparameters and configurations, and visualise training and evaluation metrics. It supports integration with popular machine learning frameworks and provides an intuitive interface for managing and analysing experiment data. You can use a github account for free registration.
With this tool you can follow along with your experiments live.
Experiments
We performed a bunch of experiments to see what settings can improve the winning rate of our agent. Below we are listing the parameters that have been adjusted based on the experiments’ results.
Hyperparameters
- Epsilon increment. Balances exploration and exploitation during the learning process. The initial epsilon value is 0 (agent makes only random moves in its environment) and it is subsequently incremented till it reaches 1 (agent makes his own decisions based on the knowledge gained during exploration). The method of gradually increasing the exploitation rate (epsilon) during the training process is commonly referred to as "epsilon-greedy decay". Final applied value: 0.0001.
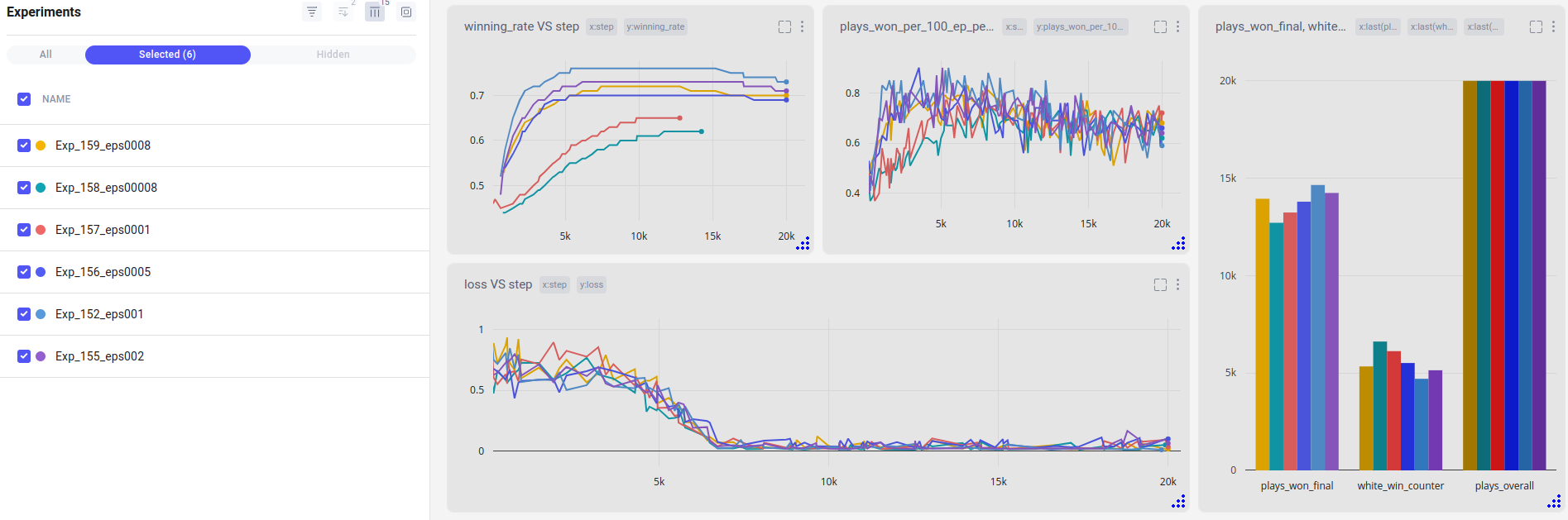
- Batch size. The number of transitions sampled from the replay buffer (memory) at each iteration of the learning process. A larger batch size means that more experiences are considered simultaneously, which can lead to more stable updates and better utilisation of computational resources. However, larger batch sizes also require more memory and computational power. Commonly used batch sizes in deep reinforcement learning algorithms range from small values like 32 or 64 to larger values like 128 or 256. Final applied value: 64.
- Learning rate. The learning rate is a hyperparameter that controls the step size at which the optimizer (we use the Adam optimization algorithm) updates the model's parameters during the training process. A higher learning rate allows for larger updates, which can lead to faster convergence but may also risk overshooting the optimal solution. Typical learning rates for Adam optimizer in deep reinforcement learning can range from small values like 0.0001 or 0.001 to larger values like 0.01 or 0.1. Final applied value: 0.00025.
Neural Network Architecture
- Type of neural network. We considered 2 types of neural network to deploy in our agent - Feed Forward Neural Network (FFNN) and Convolutional Neural Network (CNN). After some experiments we could see much quicker results when using a FFNN, that’s why we decided to stick to it. Although using CNN could be quite promising, we simply did not have enough time to investigate it, like we did with FFNN. Final applied architecture: FFNN.
- Number of hidden layers. With more layers, the network can potentially capture and model more nuanced features and decision boundaries relevant to the DDQN agent's learning task. On the other hand, training a deep network can require more training time for it to converge. It could also increase the risk of overfitting (to fight that, we used a regularization technique called Dropout after each layer). Final applied architecture: 2 hidden layers with dropout value of 0.2 for regularization.
DDQN Agent Parameters
- Number of iterations before updating the target network. Defines how often we copy our main model’s parameters over to the target model parameters. By copying the parameters from the policy model to the target model, we freeze the target network's parameters for a certain period. This helps stabilize the target network and prevents it from changing too rapidly, providing a more consistent estimate of the Q-values. Updating the target model less frequently also allows for more exploration but may result in slower convergence. On the other hand, if we update the target network too frequently, the agent may converge quickly but may not explore alternative actions thoroughly. Final applied value: 200.
- Number of iterations to synchronise the weights with the white player. A larger value means that the black agent will have more stability in its learning process and more time to master his strategies. It will be exposed to a more consistent opponent (the white agent) that follows a similar strategy. But this way it will also mean less adaptation and less possible strategies, the black agent has the chance to play against. Final applied value: 2000.
Using the specified parameters, we trained our model and saved its state, when it achieved the winning rate of 90% for 100 plays playing against the white agent. During validation against random, our agent achieves over 70%.
Conclusion and Future Research
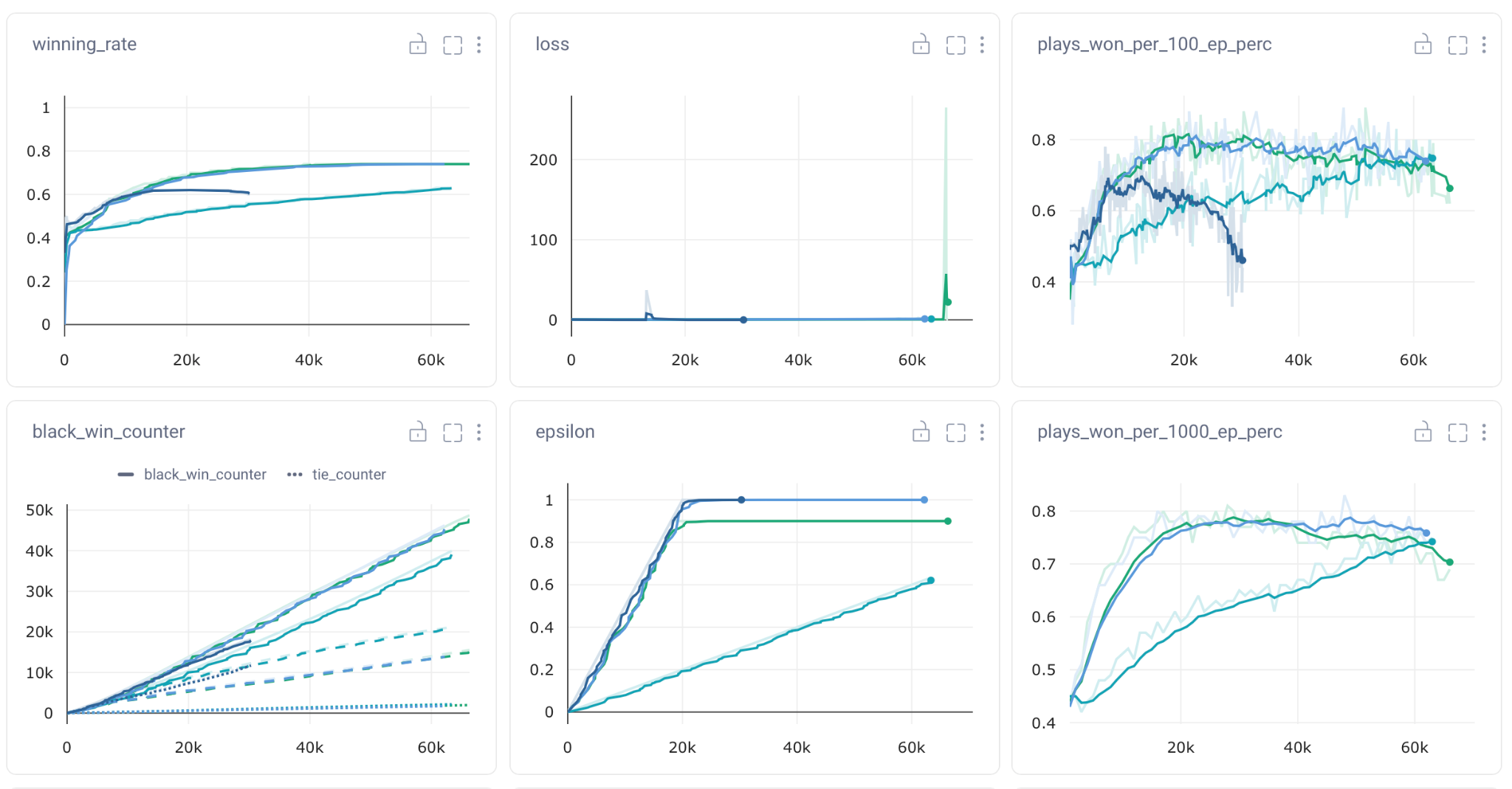
This is an example illustrating a typical training run in our setting. It showcases the win rate over 100 and 1000 games and the progression of the loss curve.
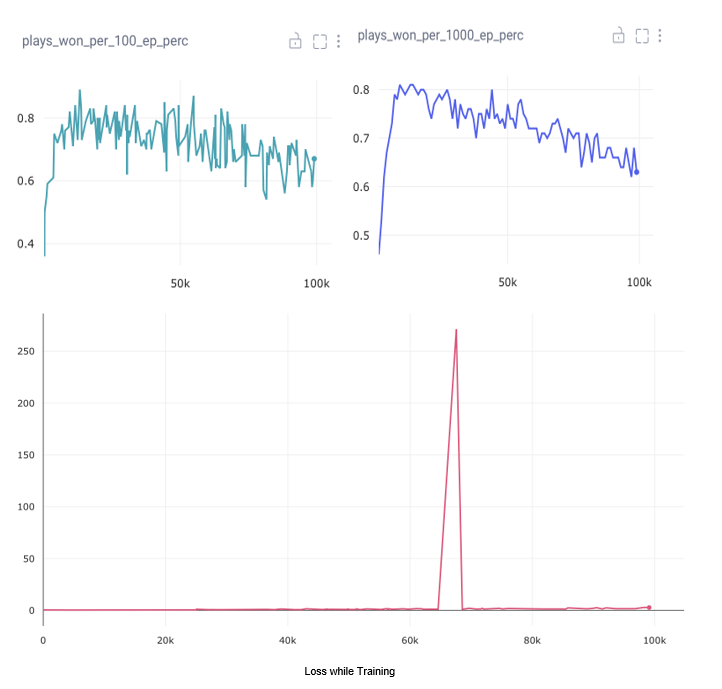
As observed, we swiftly achieve a relatively high win rate that gradually diminishes over time.
The loss curve starts at a low level from the beginning but exhibits a slight increase towards the end.
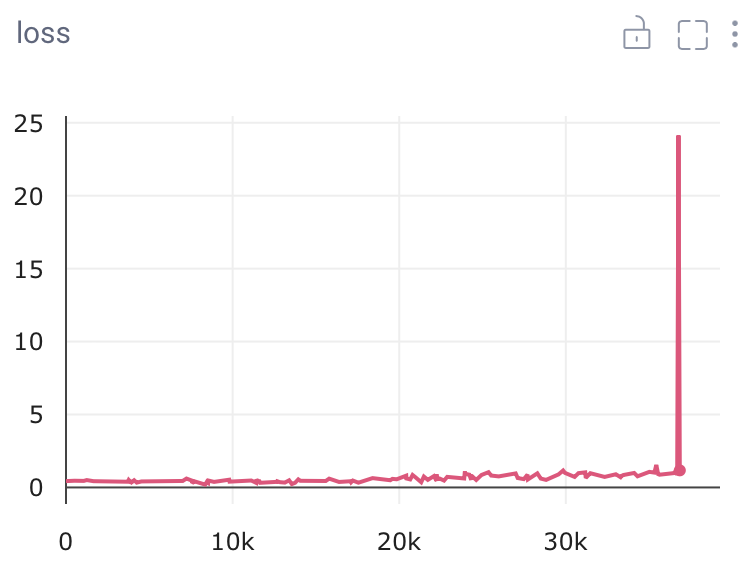
What is the underlying cause? Our hypothesis is overfitting.
But whenever we try to make the model bigger, the loss keeps going up steadily. As you can see in the graph below.
Our Literature and the sources of code
Theory on Double Q-Learning:
van Hasselt, H., Guez, A., & Silver, D. (n.d.). Deep Reinforcement Learning with Double Q-learning. Retrieved July 4, 2023, from www.aaai.org
van Hassel, H. Double q-learning. In J. D. Lafferty, C. K. I. Williams, J. Shawe-Taylor, R. S. Zemel, and A. Culotta, editors, Advances in Neural Information Processing Systems 23, pages 2613–2621. Curran Associates, Inc., 2010.
For code:
https://github.com/xyqfountain/Othello-Reversi-Env-for-Reinforcement-Learning
https://github.com/colinmsnow/othelloAI
https://towardsdatascience.com/double-deep-q-networks-905dd8325412