Playing Othello with a CNN
Board games and artificial intelligence have long been closely linked. Even in the early days of AI research in the 1950s, games like chess and checkers were used as testbeds for algorithmic decision-making. Because of their controlled environment with clear rules, they are ideal for developing AI. But advances in AI in recent years have taken this connection to a whole new level. Today, algorithms are able to outperform human experts in complex board games such as Go, chess, and even poker.
As part of the “Deep Learning” course of the master's program in computer science, we were given the task of using artificial intelligence to create an agent that plays Othello. The goal was not to outperform existing Othello AIs. Rather, the journey was the destination – the implementation of a completed project, with a clearly defined goal.
This blog post describes how we approached this task and set out to create, train, and improve a Convolutional Neural Network (CNN) for the board game Othello. Othello, also known as Reversi, is a strategic game for two players with simple rules but complex gameplay.
The basics
How to play Othello
The first step towards becoming a playable Othello agent is understanding the rules and gameplay.
Othello is a strategic board game for two players played on an 8×8 game board. The objective of the game is to have the most pieces of your color when the board is completely filled.
At the beginning of the game, four tiles are placed in the center of the board, two of each color. Players take turns placing a tile of their own color on the board. In doing so, they must place a piece in a position that is horizontally, vertically, or diagonally adjacent to an already-placed piece of the opponent's color, with only pieces of the opponent's color between the new piece and the already-placed piece.
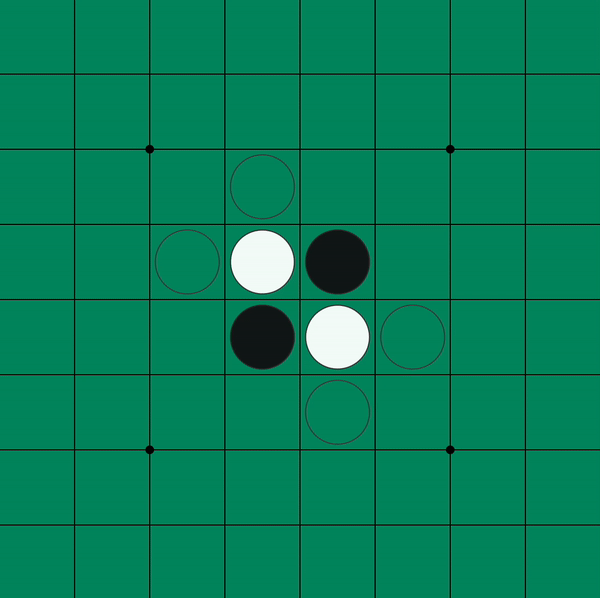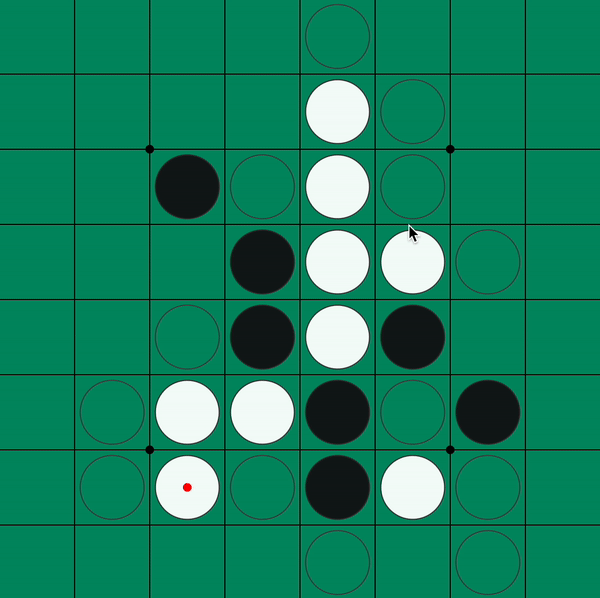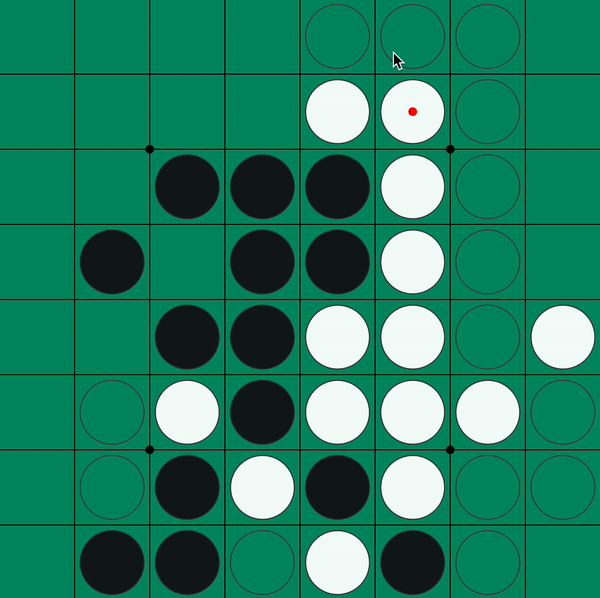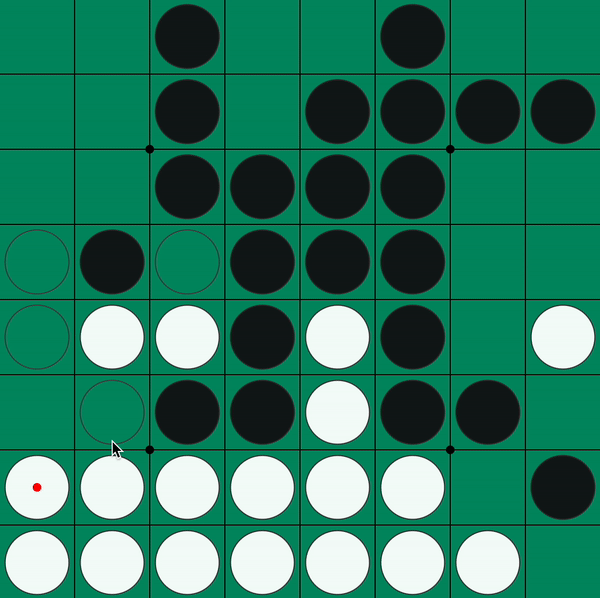
Figure 1: Beginning moves of an Othello game
When a player places a token that causes opposing tokens to be trapped between two of their own tokens, those opposing tokens are flipped over and take on the color of the current player. Flipping the tiles allows players to control the board and place more of their own tiles.
The game ends when the board is completely filled or no player can make any more valid moves. Then the tokens of each player are counted and the player with the most tokens of his color wins.
How does the agent play?
In order to test our agent, Othello had to be implemented locally as a game. For this, a freely available Python implementation was used and adapted (Siyan, 2023).
What is a CNN?
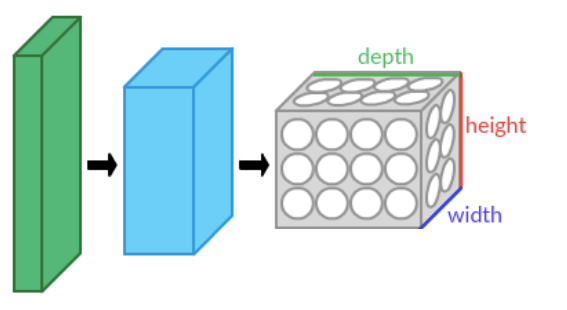
Convolutional Neural Networks (CNNs) are a type of artificial neural network specifically designed to process structured visual data such as images. They usually consist of multiple layers that use convolution and dimension reduction (pooling) to recognize patterns and features in images hierarchically. Accordingly, they are well suited for tasks such as image classification, object recognition and localization.
Implementation
Background
Before we started implementing the agent, it was worth taking a quick look at existing approaches and projects.
Arguably, some of the most well-known projects in the world of artificial game agents include AlphaGo, AlphaGo Zero, and AlphaZero by DeepMind. AlphaGo is based on a supervised training approach using neural networks combined with Monte-Carlo Tree Search (MCTS) and reinforcement learning, while AlphaGo Zero and AlphaZero forgo supervised training and rely purely on reinforcement learning and MCTS.
AlphaGo uses CNNs, among other things, so it uses convolutional operations to recognize spatial patterns. This is for the following reason:
As explained above, CNNs are particularly good at recognizing patterns and features in visual data such as images. A Go board state can be interpreted as well as an image: An image is a two-dimensional array of pixels, which can take on different color values. A Go board state is a two-dimensional array of playing fields, which can assume different states (black, white, empty). Thus, as with an image, a CNN can analyze the visual properties of the board and pieces and identify patterns relevant to game strategy.
Othello is similar to Go in terms of board structure. Therefore, just like in Go, CNNs can be trained well with Othello board states.
This idea was taken up in a paper by Liskowski et al. in 2017 (Paweł Liskowski, Wojciech Jaśkowski, Krzysztof Krawiec, 2018).
In it, a CNN is used to select the next move in an Othello game (Move Prediction). Different CNN architectures are also tried and compared. Just like AlphaGo, Liskowski et al. also rely on supervised learning.
The network architecture of Liskowski et al. is a suitable starting point for our agent.
Network Architecture
We were guided by the network structure of Liskowski et al. as mentioned above.
The CNN consists of several convolutional layers, with different numbers of so-called feature maps. There are layers with 64 and 128 feature maps. Each of these feature maps is computed using 3×3 filters, where the filters slide over the input image (the Othello board). The so-called stride (offset) is 1, so that no information is lost.
The state of the Othello board is given as input to the first layer of the CNN. The state is represented as three separate 8×8 binary vectors. One vector contains all the player's pieces as ones, another vector contains all the opponent's pieces as ones, and the third vector contains ones at the positions of the valid moves for the current board state.
After each convolution, the output value of the layer is passed through a so-called ReLU unit (Rectified Linear Unit). This ensures that negative values are set to zero and only positive values are passed to increase the activation of the neural network. The output value is then given as input to the next Convolutional Layer.
At the end of the Convolutional Layers, there is a GlobalMaxPooling layer and two fully connected layers. The first of these layers consists of 128 neurons with ReLU activation function. The second layer, called the Output Layer, consists of K = 60 neurons, which corresponds to the 60 possible move candidates in the Othello game.
The four central squares are always occupied, as they are the starting position of each game. They are therefor ignored.
Each neuron in the output layer represents a position on the Othello board.
In order for the output values of the network to be interpreted as probabilities, they must add up to 1. This is achieved by the softmax transformation applied to the output values.
Listing 1 shows this first version of a network with 4 convolutional layers.
def conv4():
inputs=Input(shape=(8,8,3))
x=Conv2D(64,8,padding='same',activation='relu')(inputs)
x=Conv2D(64,8,padding='same',activation='relu')(x)
x=Conv2D(128,8,padding='same',activation='relu')(x)
x=Conv2D(128,8,padding='same',activation='relu')(x)
x=GlobalMaxPool2D()(x)
x=Dense(128,activation='relu')(x)
out=Dense(60,activation='softmax')(x)
model=Model(inputs=inputs,outputs=out)
return model
def conv6():
inputs=Input(shape=(8,8,3))
x=Conv2D(64,8,padding='same',activation='relu')(inputs)
x=Conv2D(64,8,padding='same',activation='relu')(x)
x=Conv2D(128,8,padding='same',activation='relu')(x)
x=Conv2D(128,8,padding='same',activation='relu')(x)
x=Conv2D(256,8,padding='same',activation='relu')(x)
x=Conv2D(256,8,padding='same',activation='relu')(x)
x=GlobalMaxPool2D()(x)
x=Dense(128,activation='relu')(x)
out=Dense(60,activation='softmax')(x)
model=Model(inputs=inputs,outputs=out)
return model
Listing 1: The network structure, with 4 and 6 convolutional layers, respectively.
Read and convert data set
Before we could train our network, we needed suitable data.
The largest freely available dataset of Othello games played by humans that we could find is the WTHOR dataset (French) of the French Othello Association Fédération Française d'Othello (FFO). It contains over 115,000 games played by professional Othello players, recorded in FFO tournaments since 1977.
The WTHOR dataset is stored in a specially specified binary format. The official documentation of the format is in French, however a translated version can be found on the Internet.
WTHOR data is stored in .wtb files. Othello games are stored in them, with each game stored as a sequence of moves. No board states are stored, so we need to reconstruct them. Since each Othello game starts with the same board state and Black always starts, the stored sequence of moves can be used to reconstruct all board states that exist during the game.
Each file starts with a header of length 16 bytes. This is followed by a data block for each game recorded in the file. The header is described in table 1. For us, only the "Number of N1" records was relevant, which indicates the number of games stored in the file. In table 2 you can see the description of a game data block.
| content | size in bytes | data type |
|---|---|---|
| File creation century | 1 | byte |
| File creation year | 1 | byte |
| File creation month | 1 | byte |
| File creation day | 1 | byte |
| Number of N1 records | 4 | longint |
| Number of N2 records | 2 | word |
| Year of Game | 2 | word |
| parameter P1: game board size | 1 | byte |
| Parameter P2: type of parts | 1 | byte |
| Parameter P3 : depth | 1 | byte |
| X (reserve) | 1 | byte |
| Table 1: Description of a WTB header |
| Content | Size | Data type |
|---|---|---|
| Tournament Label number | 2 | word |
| Black player number | 2 | word |
| White player number | 2 | word |
| Number of black pawns (actual score) | 1 | byte |
| Theoretical score | 1 | byte |
| List of moves | 60 | byte[] |
| Table 2: Description of a game data block |
We read each .wtb file from the WTHOR dataset and create a list of consecutive board states for each of the games stored in it from the list of moves. We then encode each board state as three input vectors using the format described above. Both of these are handled by the read_wthor_data() method. The read-in can be seen as a snippet in Listing 1.
Also, for supervised training of the network, we need labels (Y), which is the move following in the data set, in addition to the input data (X).
After that, we then divide the data into training data, validation data, and test data, and store it in h5 format for faster reading later.
X_full=np.ndarray([])
Y_full=np.ndarray([])
for file in wthor_path:
X,Y=read_wthor_data(f"{data_path}/{file}")
if X_full.size==1 and Y_full.size==1:
X_full=X
Y_full=Y else:
X_full=np.append(X_full,X,axis=0)
Y_full=np.append(Y_full,Y,axis=0)
X_train,X_val,X_test,Y_train,Y_val,Y_test=split_dataset(X_full,Y_full)
f=h5py.File('dataset.h5','a')
f.create_dataset('X_train',dtype='i1',data=X_train,maxshape=(None,8,8,3))
f.create_dataset('Y_train',dtype='i1',data=Y_train,maxshape=(None,60))
f.create_dataset('X_val',dtype='i1',data=X_val,maxshape=(None,8,8,3))
f.create_dataset('Y_val',dtype='i1',data=Y_val,maxshape=(None,60))
f.create_dataset('X_test',dtype='i1',data=X_test,maxshape=(None,8,8,3))
f.create_dataset('Y_test',dtype='i1',data=Y_test,maxshape=(None,60))
f.close()
Listing 1: Reading and converting the data, code snippet
Network Training
Now we can train our network. For this, we compile the model and call its fit() method. We use a callback to create checkpoints during the training. To reuse the trained model later, we save it (Listing 2).
Networks with 4 and with 6 convolutional layers were trained.
The training is supervised and based on backpropagation. So we give the network a board state, and it returns a probability distribution for possible moves. We compare this to the real move that follows this board state in the dataset, calculate an error difference. The network then changes its weights and biases – it is trained.
model=conv4()
batch_size=256
cp_path="..."
cp_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=cp_path,
verbose=1,
monitor='val_accuracy',
mode='max',
save_weights_only=False,
save_freq='epoch')
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['acc','Precision','Recall'])
history=model.fit(X_train,Y_train,batch_size=batch_size,epochs=25,callbacks=[cp_callback],validation_data=(X_val,Y_val))
model.save('models/conv4')
Listing 2: Network Training
Play test
After training, we conducted several experiments to evaluate performance. First, we had the networks play 1000 times against a random agent that randomly selects moves. The conv4 network achieved a win rate of about 80%. conv6 was slightly below that, but was also clearly better than the random agent.
However, we realized that playing against the random agent is not sufficiently meaningful, since it is relatively easy to beat. To better compare conv6 and conv4, we decided to have the networks play against each other.
However, there was a problem with this approach: since every forward pass through the network is deterministic, all games between the two networks went the same way.
To get around this, we had a random agent perform the first 6 moves of a game and only used our trained networks later. In this way, the course of the games varied, and each game became unique.
Greedy Agent
Despite this change, we still lacked a meaningful basis of comparison for evaluating network performance. In various academic papers on Othello, this is done by playing against the agent Edax, a strong, highly optimized open-source Othello agent. To implement this would have required another elaborate client implementation, so we chose not to do so.
Instead, we created a simple Greedy agent as an adversary for our networks. For each possible move, the Greedy Agent evaluates how many black and white pieces would be on the board after the move, and selects the move that would result in the most pieces of its own color.
Further considerations
During the training process, we found that the use of GlobalMaxPooling was more of a hindrance than a benefit, as it resulted in the loss of spatial information in the feature maps. To address this issue, we replaced the GlobalMaxPooling layer with a flatten layer, which converts the feature maps to a flat vector but retains the spatial information.
def conv4():
inputs=Input(shape=(8,8,3))
x=Conv2D(64,3,padding='same',activation='relu')(inputs)
x=Conv2D(64,3,padding='same',activation='relu')(x)
x=Conv2D(128,3,padding='same',activation='relu')(x)
x=Conv2D(128,3,padding='same',activation='relu')(x)
x=Flatten()(x)
x=Dense(128,activation='relu')(x)
out=Dense(60,activation='softmax')(x)
model=Model(inputs=inputs,outputs=out)
return model
Furthermore, we have removed duplicates from our data set. This ensures that each combination of board state and subsequent move occurs only once in the dataset.
To better evaluate the performance of our network, we introduced a winrate. Here, we assigned a point to each win, while a loss receives no point. In case of a draw, half a point is assigned. Then, all points are added and divided by the number of games played. This evaluation method allows a clearer assessment of the performance of our network during the training process.
We had all network versions play 1000 times against the Greedy agent.
Figure 2 shows the winrate of the different versions against the Greedy agent. In Table 3, the network names are explained.
It can be seen that the networks with a flatten layer play significantly better than networks with a GlobalMaxPooling layer. Networks with 6 convolutional layers perform slightly better.
Interestingly, the dataset without duplicates does not make a significant difference to the dataset with duplicates for 6 Convolutional Layers and one flatten Layer – unlike for 4 Convolutional Layers.
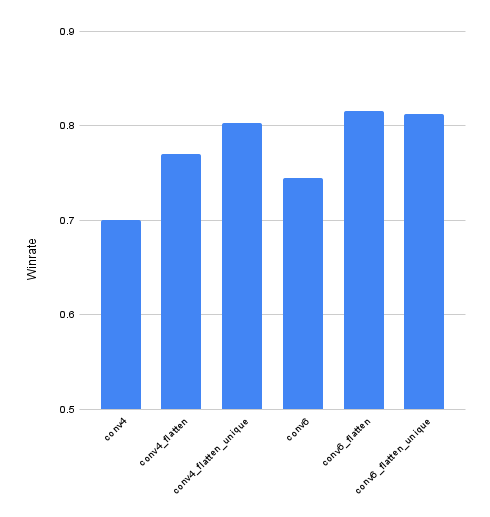
Figure 2: Winrate of the different network iterations as a bar chart.
| Name | Structure | Epochs |
|---|---|---|
| conv4 | 4 Convolutional Layer, Global Max Pooling Layer | 25 |
| conv4_flatten | 4 Convolutional Layer, Flatten Layer | 25 |
| conv4_flatten_unique | 4 Convolutional Layer, Flatten Layer, Dataset without Duplicates | 25 |
| conv6 | 6 Convolutional Layer, Global Max Pooling Layer | 7 |
| conv6_flatten_unqiue | 6 Convolutional Layer, Flatten Layer, Dataset without duplicates | 25 |
| Table 3: Legend of network names |
Conclusion
In our project, we gained insight into the steps necessary to create an artificial game agent – in our case, a CNN. We had to overcome several challenges, such as pre- and post-processing a dataset and finding a suitable validation base.
In several iterations, we have already made some improvements and tried them out. We found that using GlobalMaxPooling was more of a hindrance, and instead used a flatten layer to retain spatial information in the feature maps. We also removed duplicates from our dataset to avoid redundancy and allow more efficient use of the data.
Furthermore, we had the network play against a random agent to get a rough estimate of its performance. Although it was successful against the random agent, this assessment was not meaningful enough. Therefore, we extended the training process by having the network play against itself, with the initial moves performed by random agents. This resulted in more diverse games and allowed for a better evaluation of network performance. Also, using a winrate and a greedy agent as an opponent, we created a comparable validation base.
As a next step, we could have the trained network play against other established Othello agents, such as Edax, to further evaluate its performance. A comparison with such agents would provide us with valuable insights into the strengths and weaknesses of our network.
In addition, we could further optimize the training process by adjusting various hyperparameters, such as the network architecture, learning rate, and number of training epochs. Through these fine-tunings, we can further improve the performance of our network.
Overall, we have established a solid foundation for training and evaluating our Othello network. With further experiments and improvements, we can continue to increase the performance and robustness of the network and further extend our results.