Playing Othello with a Reinforcement Agent
Contents
Introduction
In the summer term 2023 we learned the basics of artificial neural networks in the course Deep Learning with Prof. Dr. Bastian Beggel. Depending on the field of application, different learning methods are used. There are three main categories: supervised, unsupervised and reinforcement learning.
Motivation
Reinforcement learning is a part of machine learning. Here, an agent independently learns strategies to maximize the (positive) rewards it receives and to avoid negative experiences. Alternatively, the strategy is also referred to as a policy.
The goal of this project is the implementation as well as the composition of various software parts for the realization of a self-learning agent. This agent should be able to play Othello according to the rules and achieve the best possible results. As a conclusion of the project a tournament between the developed agents will take place.
Othello
Othello - also called Reversi - is a strategic board game for two people. It is played on an 8x8 board, on which the players alternately place white and black pieces. One player always places the white pieces, the other the black ones. The game begins with the starting position shown in Figure 1.
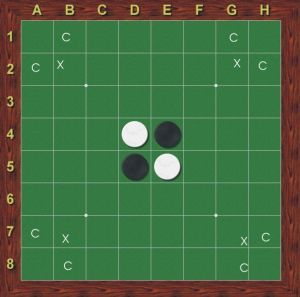
Figure 1: Othello startup arrangement.
During the game, players must place their stones on squares that are adjacent horizontally, vertically or diagonally to a square that is already occupied. When a checker is placed, the color of all opposing checkers located between the new checker and an already placed checker of the same color is changed. Moves that do not result in changing the color of opposing stones are not allowed. If a player cannot move, he is skipped. If both players cannot move or if all 64 squares of the board are occupied, the game is over. The player who has the most stones of his own color on the board at the end is the winner.
Environment and Setup
Software environment
The project as well as the application logic is written in Python 3. To separate the different Python packages a Python Virtual Environment has been created. The most important used packages are counted out in the following list:
- requests = 2.31.0
- requests-oauthlib = 1.3.1
- numpy = 1.24.3
- loguru = 0.7.0
- matplotlib = 3.7.1
- h5py = 3.8.0
- tensorboard = 2.12.3
- tensorboard-data-server = 0.7.1
- tensorflow = 2.12.0
- tensorflow-estimator = 2.12.0
- tensorflow-io-gcs-filesystem = 0.32.0
- python-dotenv == 1.0.0
A Python Virtual Environment can be created with the following command $ python3 -m venv venv. The virtual environment is now named venv. With the help of $ source venv/bin/activate the desired environment can be activated.
Game platform
As a basis for all tournament participants, a suitable game platform will first be developed. In order to play out the aforementioned tournament between different agents, an implementation of Othello is made available on a server at the university. The individual games are accessed via REST interfaces. For local testing of the developed agents, an existing Python implementation is used, see Python Othello. Both Othello backends - server and local - are accessed via wrapper classes of the game platform. Depending on the selected backend, the wrapper classes call the respective interfaces of the backend. Based on this general game platform, tournament participants can involve their agents in choosing the next move.
Realization
The following subchapters 3.x describe the structure of the project and the individual components. This includes the implementation of the agent and its environment. Also some details like the alpha-beta search or the architecture of the neural network (Convolutional Neural Network).
Reinforcement Learning and Agent
The OthelloPlayer class encapsulates one potential individual player at a time. The create_model() method is used to build a 6-layer Convolutional Neural Network (CNN) step-by-step. create_model() is called when the player is initialized. The following section describes the first convolution layer:
main_input = Input(shape = (3,8,8))
c1 = Conv2D(LAYER_SIZE, (3,3), activation = 'relu', padding = 'same')(main_input)
b1 = BatchNormalization()(c1)
c2 = Conv2D(LAYER_SIZE, (3,3), activation = 'relu', padding = 'same')(b1)
b2 = BatchNormalization()(c2)
c3 = Conv2D(LAYER_SIZE, (3,3), activation = 'relu', padding = 'same')(b2)
b3 = BatchNormalization()(c3)
a3 = Add()([b3, b1])
Each player has his own history (self.experience = []). Initially this history is empty. As soon as a training is started via the OthelloController - using the play_two_ai_training(...) method - various board states (state_array) and their corresponding reward are stored using the add_to_history() method.
Info: The state_array is rotated and thus stored in all four possible directions.
The train_model() method selects random moves from the player's history (history = self.experience) and then trains with these board states: self.model.fit(x = inputs, y = answers, verbose = 1). After the model (CNN) has been trained with various hyperparameters, such as learning_rate, it can be used in the policy() method. The policy() method specifies what the neural network suggests as the best move in combination with the alpha-beta search. The special feature of the policy() method is to call or use the alpha-beta search with: decision_tree = AlphaBeta(self.parent). In addition, the OthelloPlayer class has a load() and save() method, which can be used to load / save the weights of the model.
The OthelloController manages multiple players. Playing the games as well as training is done via the play_two_ai(...) method. Games can also be played in the main method. Besides the Othello Player there is also a BasicPlayer and RandomPlayer. These two players do not need load() or save() methods.
One of the most important attributes in the OthelloController class is self.population. This attribute is where the players are managed. Initially, an OthelloPlayer and a RandomPlayer are created. Via OthelloScript.py and OthelloInterface.py the OthelloController can be reached. Via the main method of the OthelloController class the play_two_ai(...) method can be called and then trained. Basically four games are played:
1. OthelloPlayer vs OthelloPlayer
2. OthelloPlayer vs RandomPlayer
3. RandomPlayer vs OthelloPlayer
4. RandomPlayer vs RandomPlayer
Then train_model() is called with an updated history. The OthelloController also has save() and load() methods. In addition, an import_model() and export_model() method has been implemented. The format of the model (CNNs) is after the export in a h5 format (example: Model_200.h5).
Alpha-Beta-Search
The decision which move to play next is not made directly by the neural network in the strategy pursued here, but is determined by a search algorithm. The neural network is used by the search algorithm to evaluate potential game states.
The search algorithm used is the alpha-beta search. This algorithm is an optimized variant of the minimax search method and eliminates the need to traverse the entire search tree. If a minimax search tree has x elements, an alpha-beta search tree has a root x number of elements.
The search is performed based on two values, alpha and beta. They represent the minimum score promised to the maximizing player and the maximum score promised to the minimizing player, respectively.
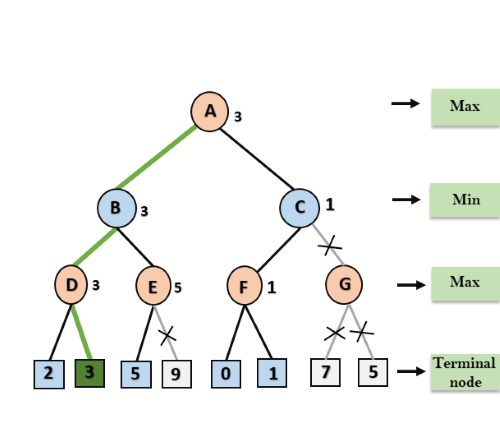
The maximizing player is always ourselves, who make the decision of the next move. The minimizing player is our opponent, who will play a response to our move. Based on this distribution, a search tree looks like the one shown in Figure 2.
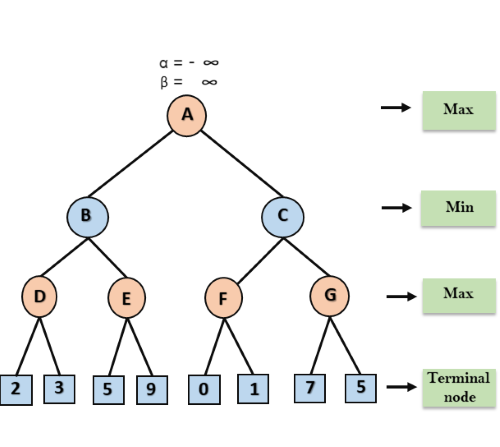
Figure 2: alpha-beta search tree.
The root node in Figure 2 represents the current game state. At this level, an attempt is made to maximize the outcome. The children of the root node represent the game states that the player can achieve with the current possible moves. At this level, the results should be minimized. The reason for minimization is that the game state on this level is considered from the opponent's point of view. The opponent tries to create a game state with his move that leads to the lowest possible result for the player. In the next level, the game state is then again viewed from the player's point of view, who of course tries to maximize his result. In the last level are the actual expected values for these game states. The search depth is defined by a parameter and corresponds to a depth of 3 in Figure 2.
When the alpha-beta search is applied to the search tree from Figure 2, the alpha value is initialized to -∞ and the beta value is initialized to +∞. The alpha and beta values are then passed to the next respective child node until the search depth is reached. For better comprehension of the next section, the search tree traversal described there is shown in Figure 3.
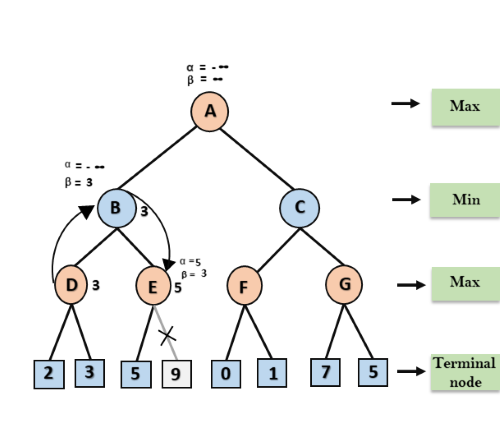
Figure 3: Starting a run through the alpha-beta search tree.
Arriving at node D, the maximum of 2 and 3 is calculated and the result is stored in alpha of D. Since the maximum of all child nodes of D is thus calculated, alpha of D is used as a new candidate for beta of B. In B, the minimum of the current beta of B (+∞) and the new candidate (3) is now calculated and stored in Beta. In the next step, the values alpha (-∞) and beta (3) of B are passed to another child node of B, i.e., E. There, the maximum of the current value of Alpha and the value of the first child node of E is calculated and stored in Alpha. Alpha is now greater than beta, which is why the further child nodes of E need no longer be considered. This is because in the plane of B the result is minimized and therefore the node E would not be selected by the adversary anyway. After that, beta of B is used as a new candidate for alpha of A. In A, after calculating the maximum from the current alpha of A (-∞) and the new candidate (3), alpha is overwritten with the value 3. The algorithm continues until all nodes are processed. Then, the maximum of all values of the child nodes of A is computed and the node with the highest result is selected as the best move. The fully processed tree is shown in Figure 4.
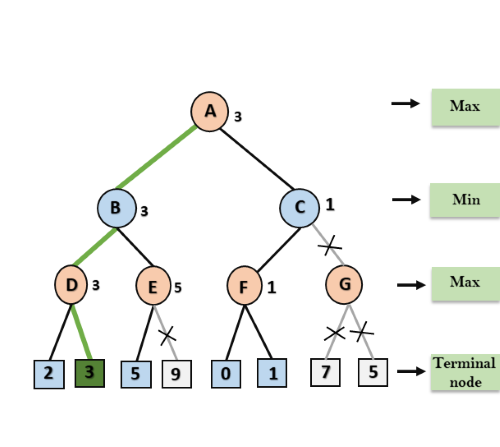
Figure 4: Fully traversed alpha-beta search tree
Repositories
In the following chapter, the two most important repositories are named and the framework in which they were used and adapted is explained.
Reinforcement Learning Othello
The reinforcement-learning-othello repository implements a classical reinforcement learning approach. In this project, a player can play against himself or a random player and learn possible (within the rules of the game) moves. The repository and its functionalities are used to generate a set of data sets.
The basic structure of the reinforcement-learning-othello repository can be equated with a multi-layer tower. There are 6 layers in total:
1. OthelloBoard
2. AlphaBeta
3. OthelloPlayer
4. OthelloController
5. OthelloArena and OthelloAgainstAI
6. OthelloInterface and OthelloScript
DL-SS23-Reversi
The DL-SS23-REVERSI repository unites the different teams of the Deep Learning SS23 (Master) event. Team 1 (Jan Brandstetter and Max Jacob) works - after splitting into the respective teams - primarily in the branch team_1.
The entry for a game is done via deepl_othello.py. Here between the different solution approaches of the teams one differentiates. For each approach a "platform" exists. Thus also a reinforcement_platform.py exists. The class OthelloReinforcementPlatform defined there inherits from the base class Othello: class OthelloReinforcementPlatform(Othello). Essential methods like convert_board(), players_turn(), enemys_turn() etc. are available.
Putting it all together
The reinforcement-learning-othello repository is primarily used to play games as well as store its results. Thereupon, the history of the games is used to train a CNN. The neural network is trained so that it can support the decision function/evaluation of a game state in alpha-beta search.
The DL-SS23-REVERSI repository is the venue of future games. In reinforcement_platform.py, the OthelloController is initialized. The following snippet demonstrates the inclusion of the OthelloController:
# setup reinforcement OthelloController
self.controller = OthelloController(path=PATH, population_size=1, epsilon=5)
self.controller.import_model(model_path)
self.player = self.controller.population[0]
Conclusion
This section reports the personal experiences and opinions of Team Reinforcement about this project.
The core idea of the project - regarding the reinforcement learning approach - has been implemented so that a player can train and learn. Three particularly positive points are to be mentioned in this respect:
- We found it very interesting to follow and execute the construction of a Convolutional Neural Network.
- the approach of reinforcement learning was new territory for us. We got a good overview as well as some details in the context of this project.
- the concept of search trees was already known to us due to our studies, but the exact functionality was deepened by this project using concrete implementations.
References
- Python Othello
- reinforcement-learning-othello
- Credits: oliverzhang42
- DL-SS23-REVERSI
- team_1