Summarizing Forum Threads Using Large Language Models
This project was a part of a master's degree lecture on Deep Learning in computer science at the Kaiserslautern University of Applied Sciences. It was conducted under the supervision of Professor Dr. Bastian Beggel.
Internet community platforms, especially discussion forums on specialized topics with a knowledgeable community, quickly grow to a remarkable size with thousands of contributions. They are characterized by their highly engaged members and the incredible amount of valuable knowledge in forum posts and threads.
An excellent example is the Audio Science Review forum, an online community of audiophiles, discussing aspects of audio equipment and audio science. Users are faced with the challenge of extracting knowledge from several hundreds of pages to obtain the information they are looking for, to participate in the discourse or educate themselves. A qualitative summary could support them and facilitate interaction with other forum users. However, summarizing discussion threads by hand would consume too many resources in terms of time and effort, a uniform style of summaries could not be guaranteed.
The progress of generative Artificial Intelligence in the field of natural language processing offers a promising solution for the automated generation of summaries of forum threads. With the rise of Large Language Models, we have a technology showing remarkable performances in understanding and generating human-like text.
We have developed and evaluated different approaches for summarizing forum threads from the Audio Science Review Forum (ASR) using state-of-the-art and open-source pre-trained Large Language Models (LLM). We implemented a deployable system, including automatic data retrieval and preprocessing from the ASR forum backend, a web-application as user-interface and our final GPU-accelerated LLM summarization approach.
Audio Science Review Forum
The Audio Science Review (ASR) forum is a community platform where audiophile users exchange opinions, expertise and ideas about audio equipment and audio science. Members can engage in detailed discussions, share their own experiences, and gain insights into audio technology and audio-related issues. The forum offers thorough reviews on various audio products including amplifiers, digital-to-analog converters, speakers and headphones, with a focus on technical analysis. These evaluations and reviews are primarily conducted and authored by the forum's operator, Amir Majidimehr.
The ASR forum was founded by Amir in 2016 and currently consists of more than 47,000 review and discussion threads. These comprise a total of almost 1.97 million individual posts. With thread pages holding 20 posts each, this amounts to nearly 100,000 pages of detailed discussions and user interactions. As of the most recent statistics, the ASR forum has registered more than 56,500 members.
It is known for its high level of user engagement, with some single threads accumulating hundreds or even thousands of responses. In this context, Amir himself has proposed the use of artificial intelligence to create summaries of ASR review threads and initiated a corresponding discussion (“Using AI for Review Thread Summaries?”).
Large Language Models briefly explained
Large Language Models are advanced AI models trained on huge amounts of text data from books, articles, websites and other sources. They are characterized by their ability to process and generate unspecific texts.
There is a simple way to explain how Large Language Models work: Imagine learning how to read and write by using a huge library of books. Similarly, LLMs are trained by feeding them large volumes of text data. They learn natural language grammar, vocabulary, knowledge about the world and even some reasoning skills. During training, these models don’t learn and memorize the actual text but patterns and relationships in it. For example: they understand that the phrase "cats are" is often followed by words like "cute" or "furry". When you process text with a LLM, it uses the context from the input and learned knowledge about word sequences to generate a response. In each step, the model predicts which word might follow next by calculating probabilities, includes it in the output and repeats the prediction process.
LLMs break text and words into smaller pieces, so called tokens, which are numerical representations. A model has a fixed context window size, expressed in the number of tokens it can consider when generating a text.
Requirements for ASR Forum Summaries
Through interaction with the ASR forum and feedback from members to intermediate results, we have defined and iteratively refined a collection of requirements for the summaries to be generated. These can be seen as functional as well as non-functional requirements. They served as a point of reference for evaluating and improving our summary approach during the development process:
- Factual Correctness: The summary should be based on correct facts from posts given to the AI model and the model should not make up its own information.
- Factual Language: Summaries should be written in a factual and concise language. Verbose formulations without valuable information should be avoided.
- Non-Repeating: The content in a summary should not contain redundancy, ensuring that each piece of information is unique and expressed only once.
- True-to-Context: Using only the information provided within the immediate context of the thread, without incorporating any knowledge from external sources.
- Informative for Engagement: The summary should enable readers to participate in the discussion.
- Balance of Opinions: A summary should express where the balance of opinions landed during the discussion or at the conclusion of the discussion.
- Structured: In the summary, each topic should have its own paragraph, if various topics can be differentiated.
- Additive: Information from subsequent thread posts should be appended to the summary of preceding posts.
*** Collecting ASR Forum Data
Using Large Language Models for summarizing threads means: feeding them with large text corpora holding the actual thread posts. Just like manually generating summaries, manually copying and transferring user posts would be far too time-consuming. A thread we used for testing and improving our approach was the popular discussion about “How can DAC's have a SOUND SIGNATURE if they measure as transparent?” with more than 9.000 messages and impossible to collect without automated processes.
Practically, the ASR forum backend provides an interface we can query to retrieve thread pages. The forum uses the community platform XenForo ® as a forum software. The built-in REST-API allows us to programmatically interact with many areas of the XenForo installation. However, to gain access to the API, a key with sufficient permissions must be generated by the forum’s administrator. For this project, we supported Amir in the creation of a key with read-only access, which he kindly provided us with. Technically, this project should work with any newer version of XenForo-powered forums with a REST-API.
To collect a whole thread, we must execute one request per thread page (20 posts each). We receive the data in a JSON format with the actual forum posts as HTML strings. During our data preprocessing, we remove every HTML syntax and unwanted characters, among other cleaning steps. By this we obtain the ASR forum thread in plain text, which we can use as input data for our language models.
*** Summarizing ASR Threads using LLMs
Although state-of-the-art language models have got larger context windows, in most of the cases the length is still too small to process an entire thread in a single inference run. Threads containing multiple hundreds of posts have a summed length greater than the context window of most of the available open source LLMs.
We evaluated modified models with context windows beyond 100,000 tokens, leading to sobering results. In the course of several tests, we came to the conclusion that these models are unsuitable for summaries. On the one hand, they tend to hallucinate more and lack the appropriate understanding of the text to be able to create a meaningful summary, on the other hand, their context window still would be not sufficient for a remarkable number of threads in the ASR forum. For example, the extensive discussion “Beta Test: Multitone Loopback Analyzer software” has a length of 528.587 tokens.
We had to consider an approach that breaks down the massive volume of thread text into processable, bite-sized pieces, helping to make the information more digestible for our AI model. At the same time, thereby we are no longer dependent from the length of the model’s context window as a limiting factor or factor for choosing one of the available open-source models. We decided on using the pre-trained Large Language Model Llama 3 with 70 billion parameters (Llama3:70B instruct), which showed the most promising results during our tests. To meet the requirement of factual language, the model’s temperature was set to 0.0. This is the only model hyper-parameter we adjusted.
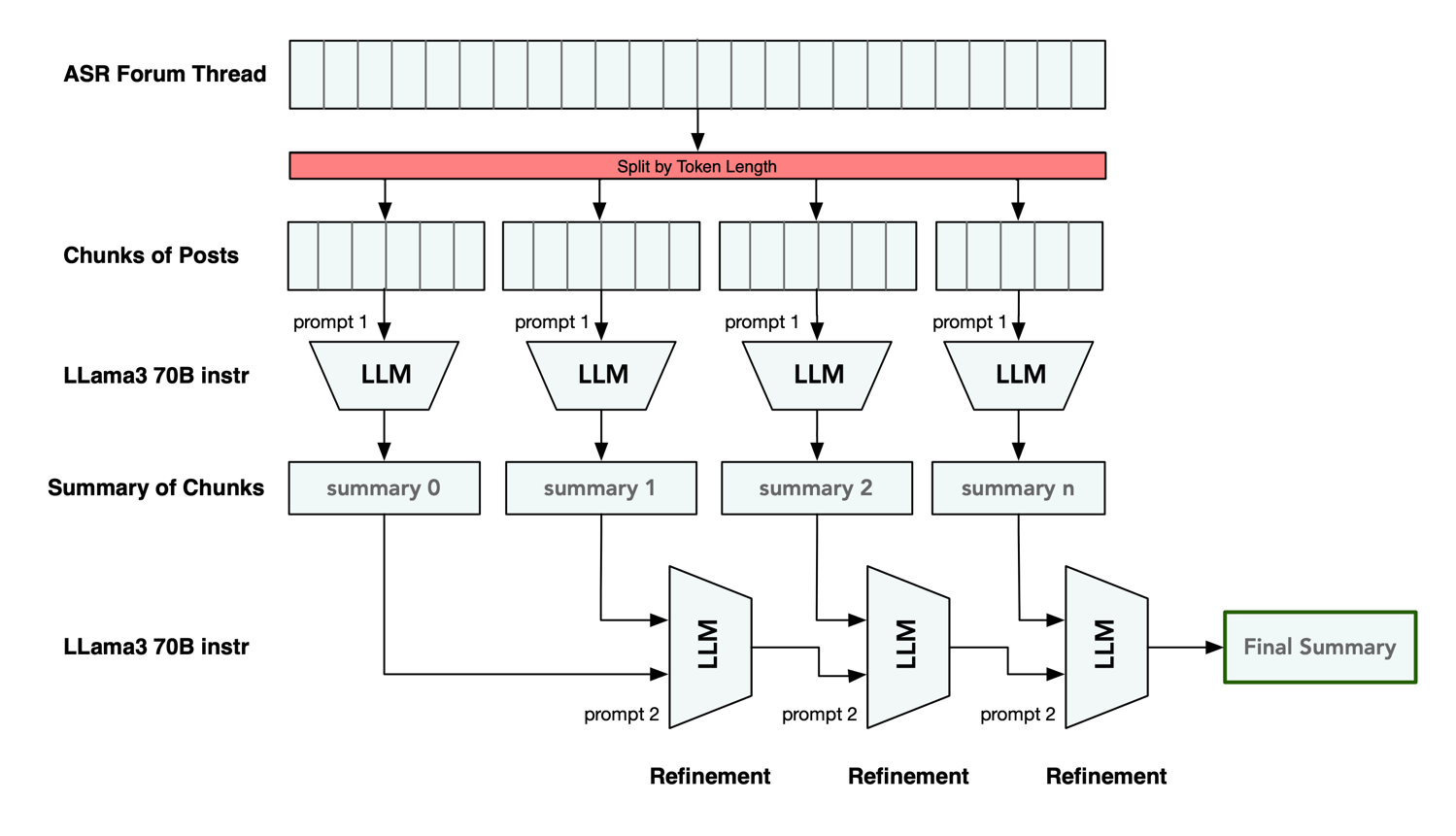
The developed and implemented algorithm for summarizing ASR threads iteratively generates summaries in multiple LLM runs. It can be described briefly with the following steps:
- Chunking: The ASR forum thread is divided into smaller groups of posts according to their length in number of tokens.
- Summarizing Chunks of Posts: Each batch of posts is processed by the LLM to generate a summary for the chunk.
- Refinement of Summary: The summary of the first chunk gets refined and extended by the LLM with information from the summary of the next chunk. This is repeated for the generated intermediated summary for all subsequent chunks, until we have a final summarization.
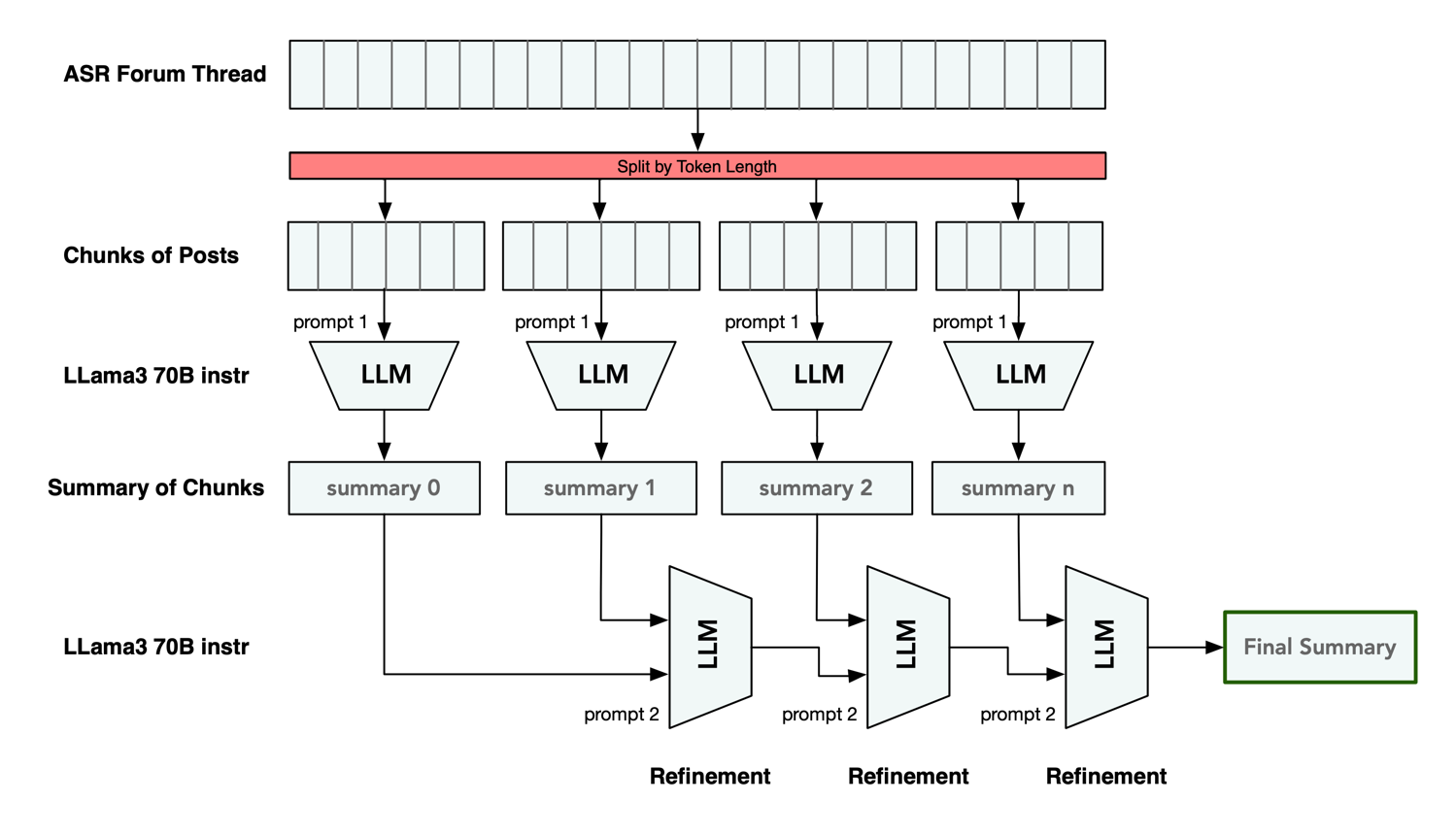
We collect an ASR thread of interest by querying the forums REST-API and preprocess the forum posts as described above. To determine the relevant size of each individual post, we use a tokenizer model to break the text into tokens. This gives us the same numerical representation of the text that the model sees and we can determine the token length per post by counting them.
The thread is split into chunk of posts according to their token length. We fill the context window as completely as possible with posts. Each batch of posts is fed to the Llama 3 language model with the aim to obtain and generate an intermediate summary as output.
In next step, the summary of the first batch, which covers the information and original topic of the initial starting post of the thread, is passed into the LLM. Additionally, the model is fed with the summary of the next batch of posts. It is instructed to refine and extend the first summary with the content of the second summary, if the second summary contains relevant information. We have thus generated an improved summary, which we will feed back into the LLM with the next chunk of posts. This step is repeated iteratively until all batches have been seen by the language model.
This approach offers the advantage of generating a new summary based on an existing previous summary without having to preprocess an entire thread again, if new posts were published in the thread.
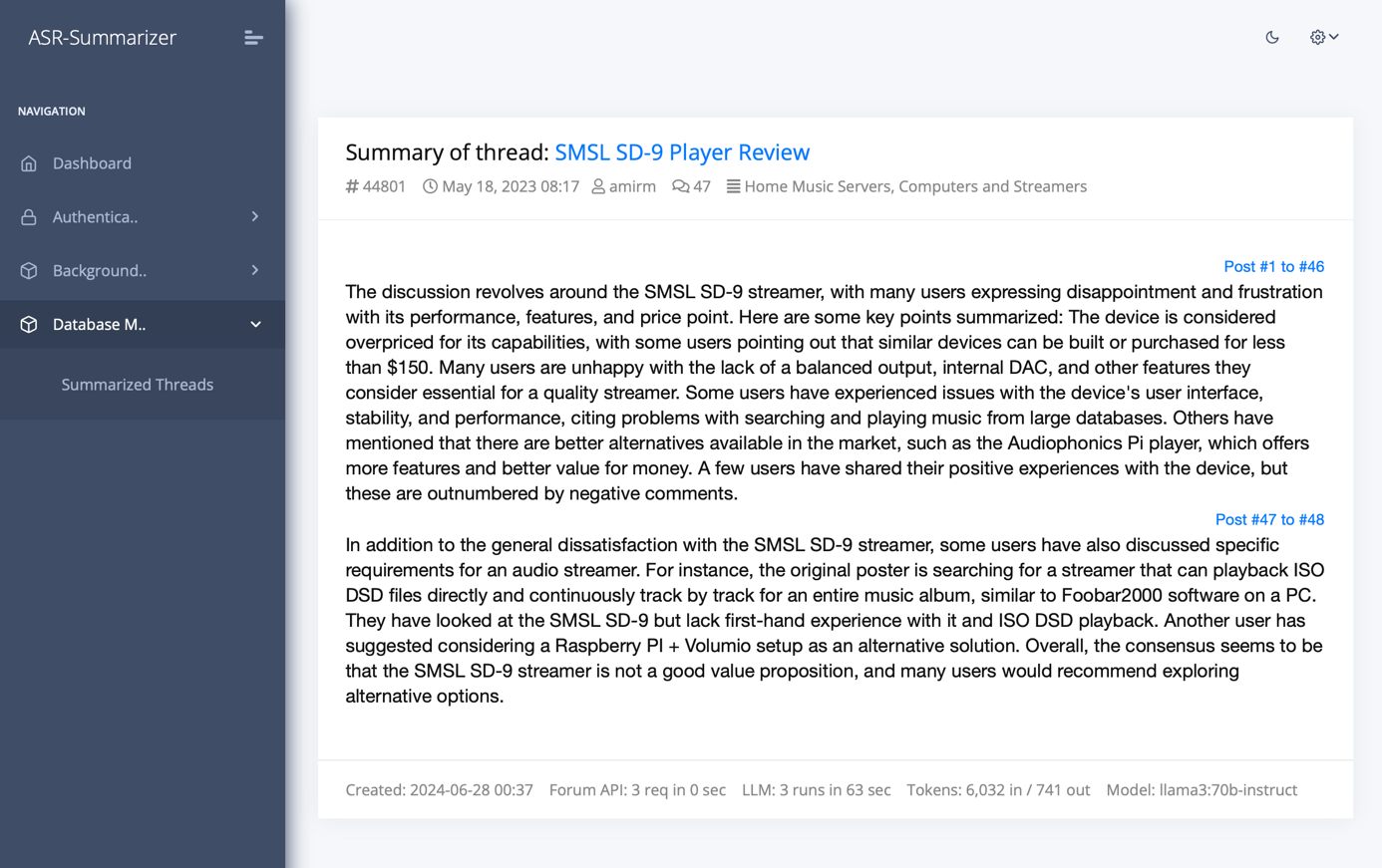
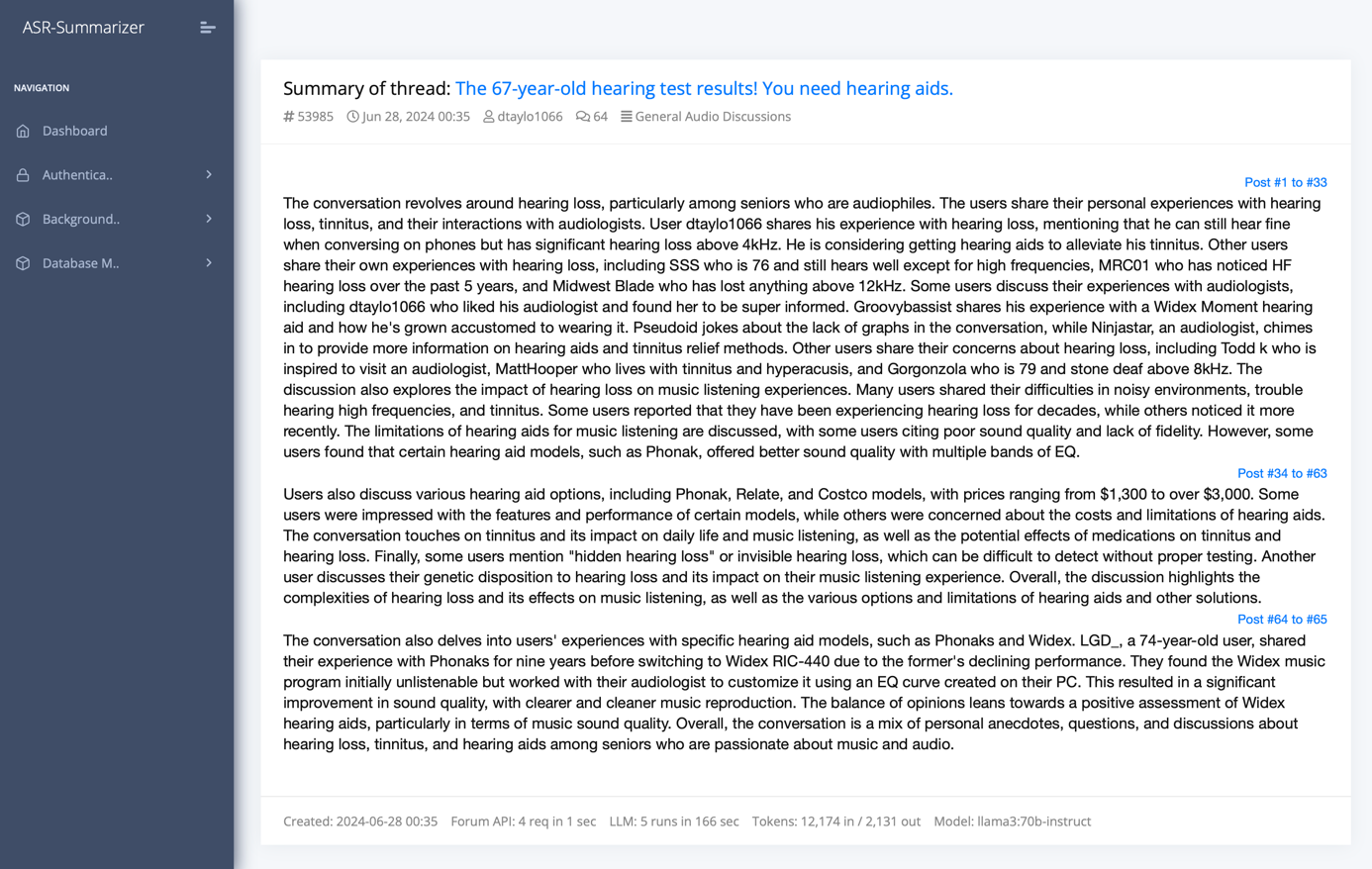
Additionally, we keep track of which range of posts the respective addition to the summary comes from. This gives us the opportunity to embed a reference to the original forum posts in the generated summary.
At the end we get a final summary of the ASR thread, for which all the information contained in the discussion or review has been processed by the AI model.
*** Designing Prompts for Iterative Summarizing
Large Language Models receive their instructions as natural language prompts. Engineering suitable prompts is an iterative process and an important part of the output optimization.
As our approach uses LLMs for two different tasks of summarizing batches of posts and the refinement of a final summary, two different prompts were thoroughly designed. Both prompts contain a listing of precise requirements the model should follow. Prompt 1 instructs the model to summarize batches of posts:
*** Prompt 1
You are tasked with summarizing chunks of posts from a forum discussion. Please ensure your summary adheres to the following detailed requirements:
Factual Accuracy: The summary must be factually correct. Do not include any imagined information or assumptions. Only include details that are explicitly mentioned in the forum posts.
No Repetitions: Avoid repeating the same information. Each piece of information should be unique and add value to the summary.
Contextual Information Only: Use only the information provided in the context of the forum posts. Do not incorporate any external knowledge or data that is not part of the forum discussion.
Reader Engagement: Structure the summary in a way that enables the reader to easily understand and participate in the ongoing discussion. The reader should be able to follow the main points and contribute meaningfully to the conversation.
Balance of Opinions: Clearly indicate where the balance of opinions landed both during and after the discussion. Highlight the consensus or predominant viewpoints that emerged as well as any significant minority opinions.
Topic-Focused: Focus on summarizing the content of the discussion rather than listing the topics that were mentioned. Provide insights into what was actually discussed about each topic.
Avoiding the Discussion Path: Do not describe the sequence or path of the discussion. Instead, focus on the key points and conclusions reached.
Paragraph Structure: Write one paragraph per topic discussed. Each paragraph should clearly cover a distinct topic or aspect of the discussion, providing a concise yet comprehensive overview.
Please apply this approach to the forum posts provided, ensuring that your summary is clear, concise, and meets all the specified requirements.
[ POST-CHUNKS ]
*** Prompt 2
Prompt 2 asks to generate a final summary, built on top of an existing summary and considering additional information from a summarized batch of posts. Additionally, we provide the model with the summary covering the initial thread post, to give it understanding of the original topic.
Your job is to produce a final summary. We have provided an existing detailed summary up to a certain point: [ REFINED-SUMMARY ]
We have the opportunity to add additional information to the existing summary to get a prolonged summary (only if needed and relevant) with some more context below.
------------
[ CHUNK-SUMMARY ]
------------
Given the new context, extend the original summary if necessary and if it relates to the overall topic below.
------
[ INITIAL-SUMMARY ]
------
If the context isn't useful or does not add valuable points to the overall topic, return the original summary. Never remove details, only add more from the given context.
Please ensure your summary adheres to the following detailed requirements:
Factual Accuracy: The summary must be factually correct. Do not include any imagined information or assumptions. Only include details that are explicitly mentioned in the forum posts.
No Repetitions: Avoid repeating the same information. Each piece of information should be unique and add value to the summary.
Contextual Information Only: Use only the information provided in the context of the forum posts. Do not incorporate any external knowledge or data that is not part of the forum discussion.
Reader Engagement: Structure the summary in a way that enables the reader to easily understand and participate in the ongoing discussion. The reader should be able to follow the main points and contribute meaningfully to the conversation.
Balance of Opinions: Clearly indicate where the balance of opinions landed both during and after the discussion. Highlight the consensus or predominant viewpoints that emerged as well as any significant minority opinions.
Topic-Focused: Focus on summarizing the content of the discussion rather than listing the topics that were mentioned. Provide insights into what was actually discussed about each topic.
Avoiding the Discussion Path: Do not describe the sequence or path of the discussion. Instead, focus on the key points and conclusions reached.
Paragraph Structure: Write one paragraph per topic discussed. Each paragraph should clearly cover a distinct topic or aspect of the discussion, providing a concise yet comprehensive overview.
Please apply this approach to the existing summaries provided, ensuring that your summary is clear, concise, and meets all the specified requirements.
*** Bringing ASR LLM Summarization into Action – Deployable Implementation
The developed approach was implemented as a modularized application which allows loading ASR threads and summarizing them GPU-accelerated with a Large Language Model in an automated process.
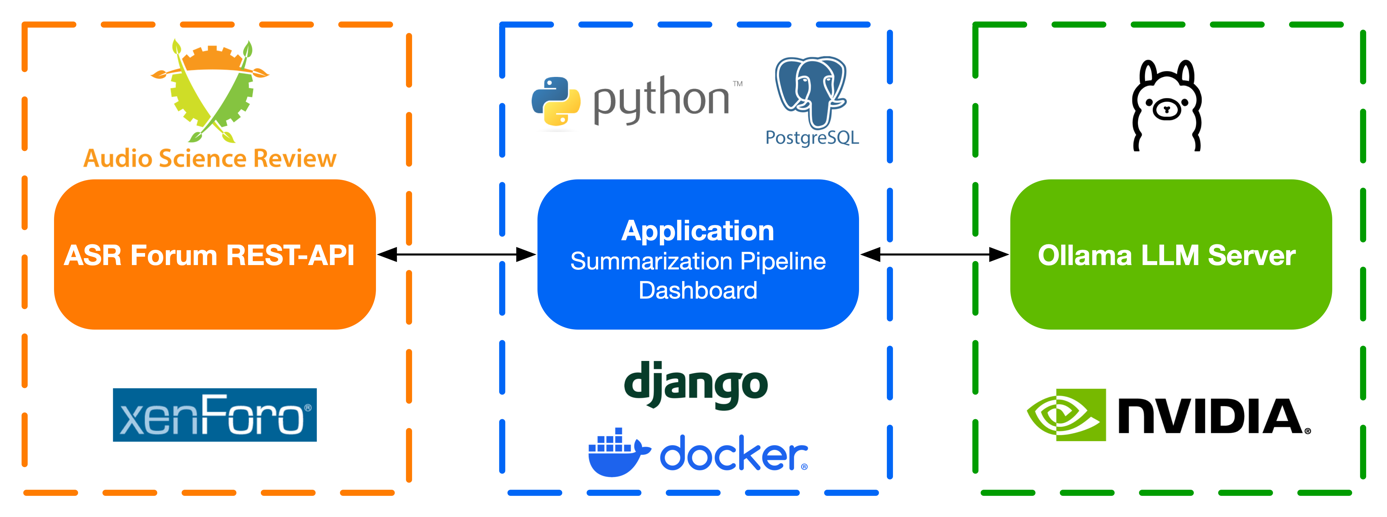
The application is built as a multi-container system and automatically sets up a web-based user-interface, a database, the server running the actual summarization algorithm and a reverse-proxy for serving the frontend. It takes care of talking to the ASR forum REST-API to collect threads to summarize them and manages the summarization pipeline for invoking the AI model to generate summaries. The summarization pipeline and user-interface are implemented in Python.
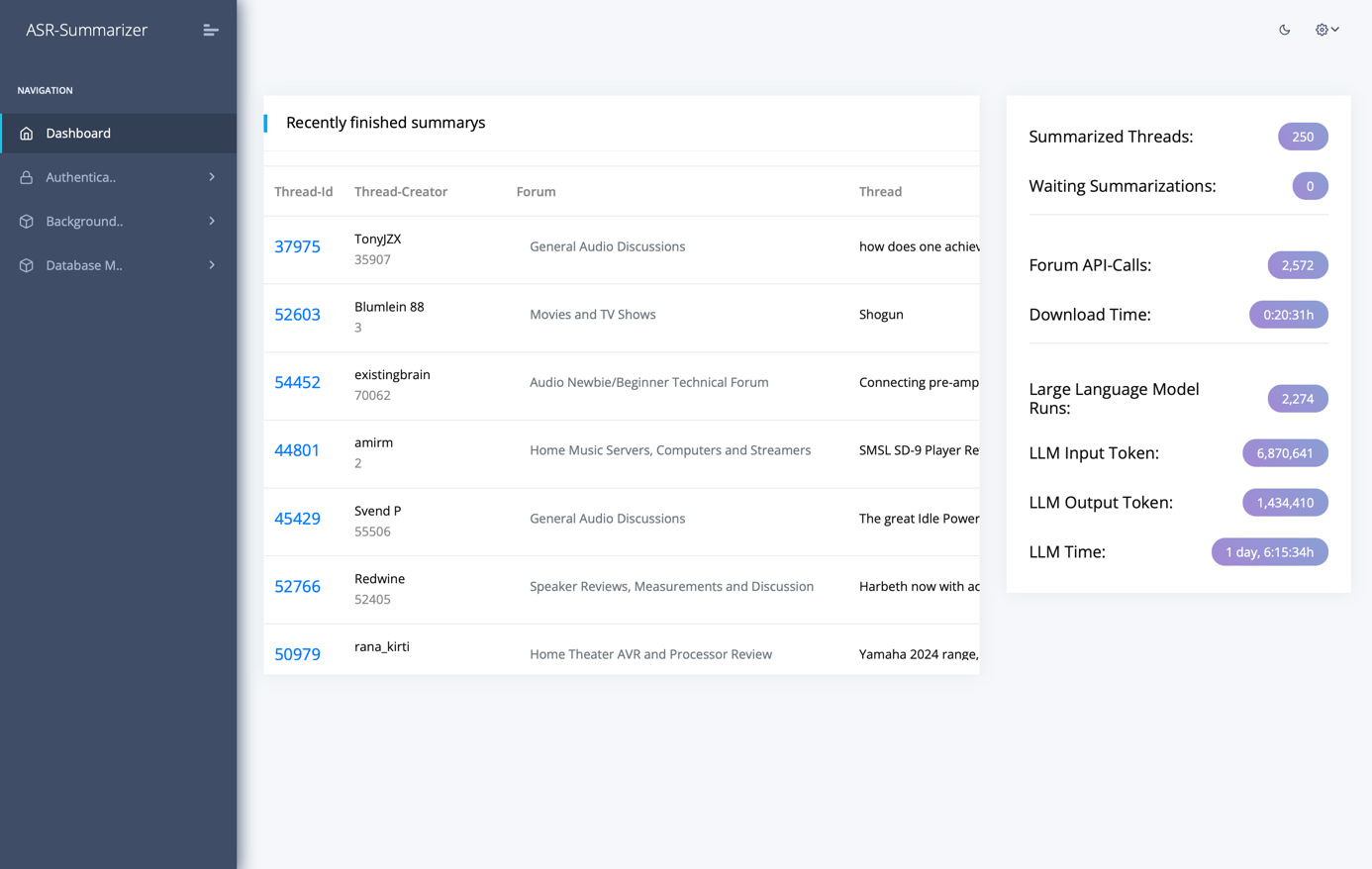
The user-interface is a dashboard that acts as a controller to initiate the processing of specified threads and to present created summaries. As soon as a user registers a new thread in the dashboard, the system adds a summarization job to a worker queue. The application then loads the thread automatically and generates a summary. To improve the user experience and enable quick access to the original posts, the injected references to posts are replaced by their corresponding forum links in the displayed summaries. This allows quick access to posts to which the summary refers without having to search for them yourself.
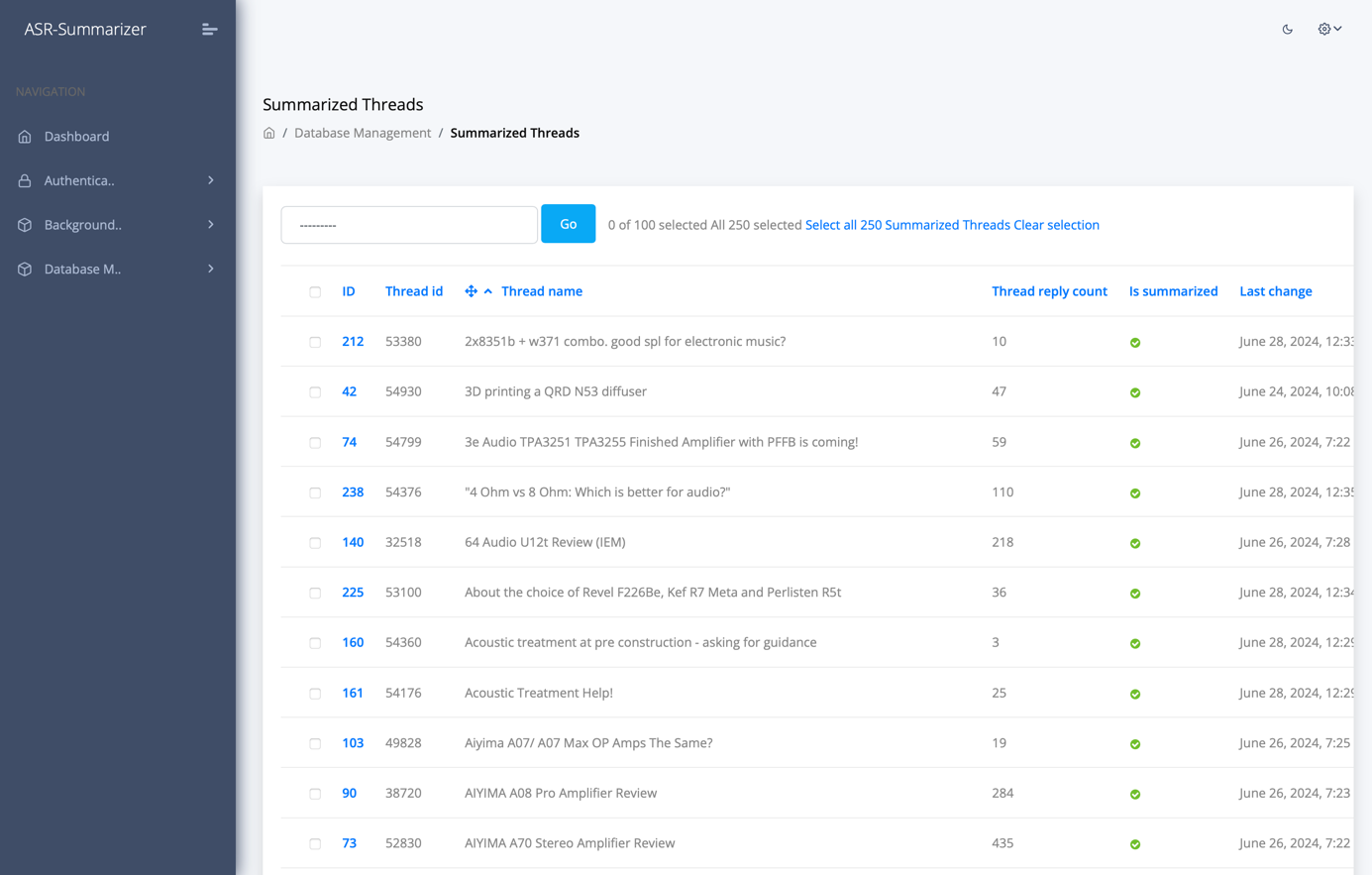
Metadata of threads like author or creation date and the generated summaries are managed in a persistent database. Additionally, metrics related to the model inference per thread, like number of runs, runtime or number of processed tokens are recorded as well.
For the LLM inference, an Ollama instance was used to deploy and serve the pre-trained Llama 3 70B model. Ollama is a framework for building and running language models. It provides a simple API for running and managing models, as well as a library of pre-built models that can be easily used. The framework can be run on local machines as well as on a server. This also applies to the application.
The used Ollama instance in this project was deployed on one of the university’s state-of-the-art and performant deep learning servers, equipped with four NVIDIA A100 GPUs with 80 GB of graphics memory each. However, for Ollama the utilization of a single A100 units was sufficient for the LLM inference. It is important to choose a GPU with enough memory for the complete model to fit in (40GB for Llama 3 70B).
We have successfully demonstrated that pre-trained and open-source Large Language Models can be used for summarizing large text data, without having to adjust the model itself by problem-specific training or fine-tuning. With our approach, ASR forum threads can be processed and summarized automatically.
Repository
The deployable implementation as well as a detailed technical documentation of our project are available in a repository on GitHub: