U-Race


Unity Reinforcement Autonomous Car Environment
Introduction to U-Race
In order to work independently of Amazon's AWS DeepRacer and the associated 10-hour training limit, the U-Race framework was developed as part of the 'Deep Learning' course at Kaiserslautern University of Applied Sciences in the 2022 summer term.
U-Race stands for 'Unity Reinforcement Autonomous Car Environment' and is the independent attempt to create a user-friendly environment in which methods of reinforcement learning can be learned in the context of autonomous driving and racing simulators.
Implementation
With the help of the provided track parts, an own racetrack can be assembled and used to train a vehicle. These assets were created originally by BEDRILL and modified to our needs. The same applies to the shown car, an american muscle car.
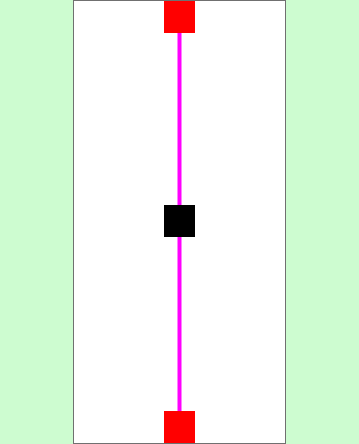
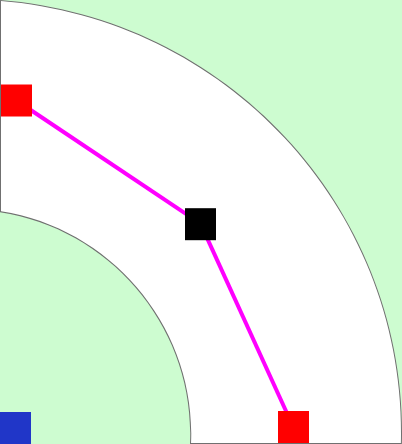
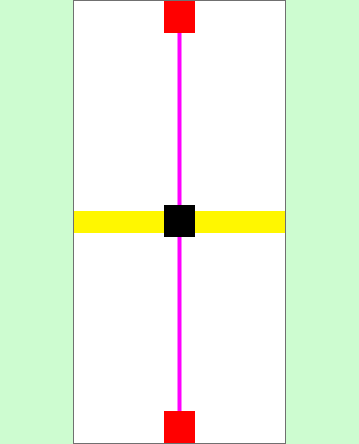
Those track sections not only have an appearance, consisting of a mesh and corresponding materials, but also colliders, which are responsible for detecting collisions between the car and the track. In addition, the sections of the route have been enriched with additional information. This information is provided in empty objects, colliders and C# scripts.
All available route sections are presented below including their additional information. These are marked visually:
-
Geometric (Empty Object and Collider)
- Start/end position of the track section (red)
- Pivot point of the model = center of the route (black)
- Position of the start/finish line (yellow)
- Center point for the radius of the curve (blue)
-
Custom data structure for processing (C# Script)
- Index of the route segment in relation to the total route
- Previous / next route segments
- Route type (straight / curve)
- Course event (start / end)
Custom Data structure of the racetrack
When starting the application, the track parts are only so-called game objects in the Unity scene. In order to obtain a representative data structure, the additional information on the individual route sections is loaded. A circular ( = double linked) list is then created with these. Each entry stands for an individual route section.
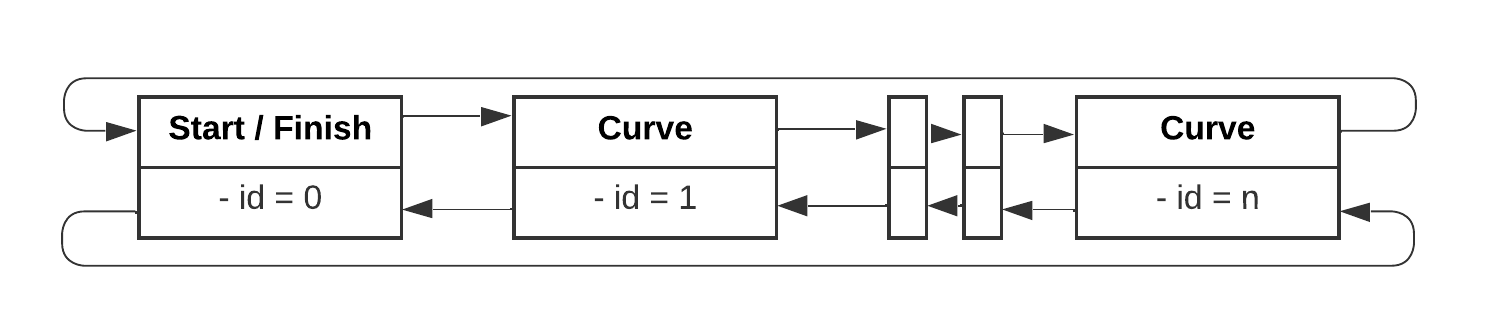
The start/end position of the line segments is used to measure which is the closest start/end position. If this distance is less than a specified value, the script decides the section to be either the predecessor or successor. After all possible connections have been formed, the direction in which the route runs is determined from the start. In addition, the start and end positions of a section are now known.
It is also validated whether the start and finish of the route can be reached. Here it is determined whether it is a simple one-way route or whether it is a circular route. If it is circular, the list is adjusted accordingly by the script.
Used frameworks
AuroAI
AuroAI is a Unity project by Auro Robotics. We found this project and the associated blog article during our research on reinforcement learning with Unity ML Agents.
The article describes how a vehicle learns itself to reach randomly appearing targets on a level. When the vehicle reaches the destination, it will disappear. At the same time, the next target appears. The trained neural network is able to approach and achieve the goals and also to reach the next.
We used the project to have a controlled launch point for Unity ML Agents. At the same time, the blog article describes problems and gives tips on how to deal with them. You can read more in our technical documentation.

ML-Agents
The Unity ML-Agents Toolkit is an open-source package which helps to integrate intelligent agents. Those can be trained by using reinforcement learning methods. ML-Agents provides an implementation of PyTorch to use state-of-the-art algorithms. We used the trained agent to control our test-vehicle on the racetrack.
Python Trainer with Config.yaml
Unity Technologies decided to write their own implementation of known state of the art deep learning algorithms. These are currently accessible deep learning algorithms:
- PPO - Proximal Policy Optimization
- SAC - Soft Actor-Critic
- MA-POCA - MultiAgent Posthumous Credit Assignment
With the Unity ML Agents implementation of the algorithms, no additionally code is needed to get started. They abstracted all parameters for the deep learning algorithms in a Training Configuration File. The Training Configuration File is written in YAML and has the file extension .yaml.
Sounds good because there is nothing to code, right?
Yes and No.
One man's trash is the other man's treasure. The trashy part is when it comes to people with knowledge in math, deep learning, and coding. If they want to try new algorithms or concepts or just want to tweak a little bit inside the implementation, it is currently not possible. But we see light at the end of the tunnel because the voices of the people, which want to customize things getting louder. Our hope is, that if everything is stable, that they allow custom implementation for the experienced community.
Because the game engine Unity is for a broad audience, like people with little to non-existing knowledge in coding or game studios without time for a custom implementation. In many cases it, satisfy the most needs of people which are playing around with deep learning.
Overall, it would be redundant boiler plate code. The solid groundwork of Unity Technologies is the treasure part for most people of their broad audience. For our use case it was more than enough, because it was hard to learn the concepts about the training algorithms, neural network settings and all possible hyperparameters.
PythonAPI
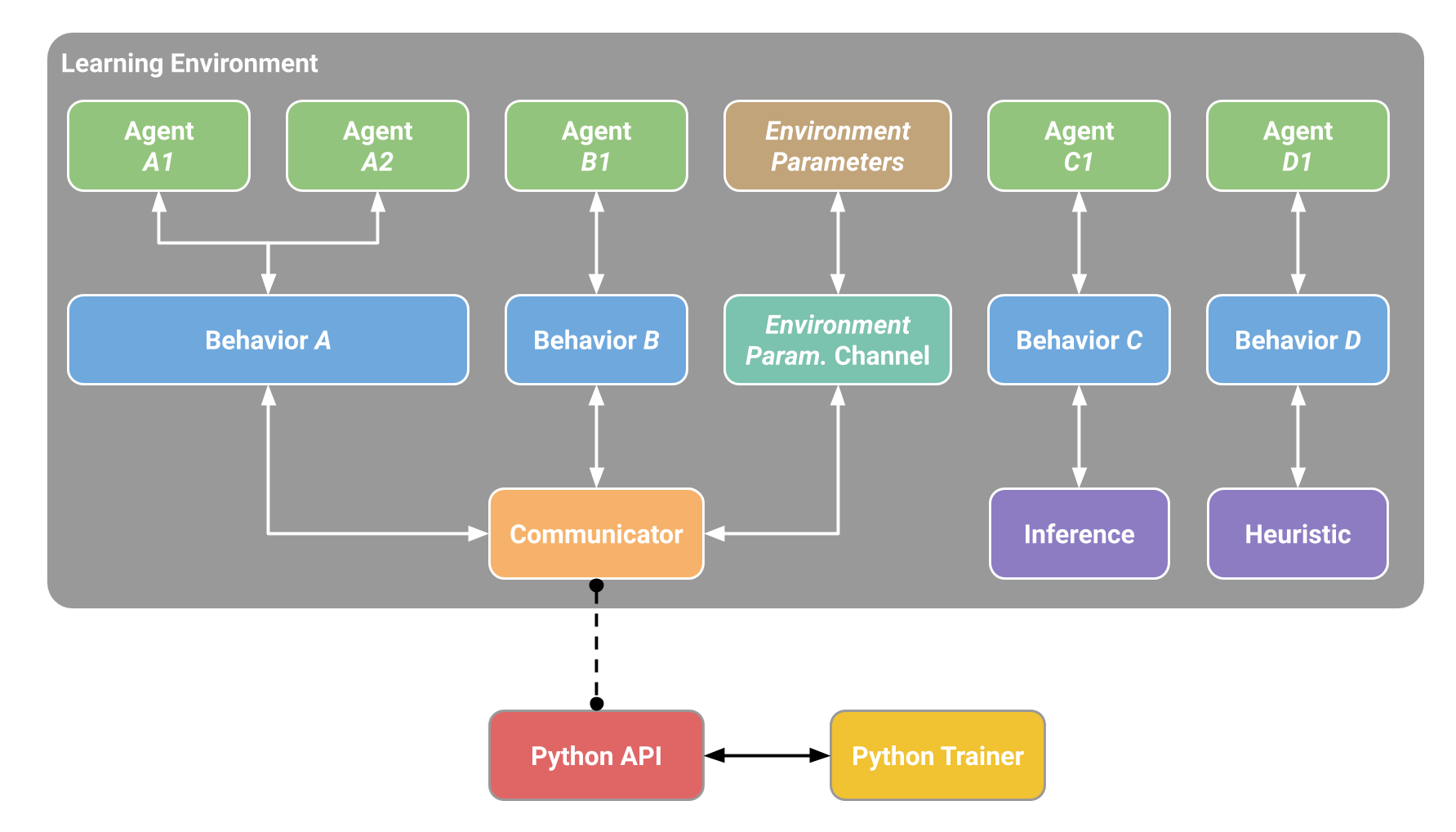
The purpose of this API is to let Agents develop in a simulation to perform reinforcement learning. On code level, the Python API exposes an entry point for the Python Trainer.
The API supports multi-agent scenarios and groups of similar agents, which use observations, action spaces and similar behavior. These Agent groups are identified by their Behavior name.
For performance reasons, data for each agent group is processed intermittently. Agents are identified by a unique id that allows agents to be tracked through the whole simulation phases. One simulation step corresponds to the simulation progress until at least one agent of the simulation sends back its observations to Python. Since Agents may require decisions at different frequencies, one simulation step does not necessarily correspond to a fixed simulation time increment.
Getting Started
To use U-Race you need a local installation of Unity, Python, Blender as well as ML Agents and PyTorch. More about the specific versions can be found in the documentation of the project. When you open U-Race, the version we used in our attempts is available for quick start.
The vehicle can also be driven manually on the track to get a feeling for the racetrack. To drive the car yourself, the behavior type of the SessionHolder object must be set to 'Heuristic Mode'. After that, the vehicle can be steered with the arrow keys (or WASD). Below you can see how we drove our first rounds around our individually assembled circuit.
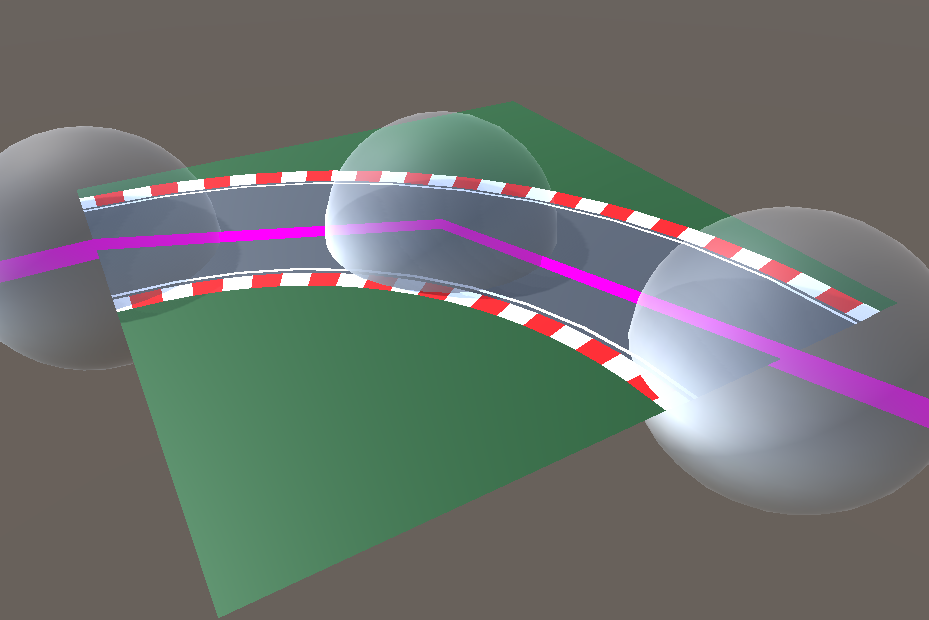
Waypoints
Waypoints are placed all over the track, which the vehicle should drive to one after the other in a fixed order to complete a lap on the racetrack. These can be hidden by the user if desired.
With the help of the additional information from the representative data structure, the pivot point and the start and end positions can be read out. These are used to calculate a sequence of waypoints on the route segment. In addition, the center line between the waypoints is used as an approximate route centerline.
Parameters
If you want to implement your own reward function, a number of parameters are available that provide information about the vehicle and the racetrack.
An overview of the most important parameters:
bool all_wheels_on_track;
bool approaching_next_waypoint;
bool waypoint_passed;
bool more_waypoints_reached;
bool reached_new_high_speed;
bool round_over;
float distance_from_center;
float speed;
float track_completion_progression;
float steering_angle;
float distance_to_next_waypoint;
float round_time;
Vector3 track_center_position;
Vector3 next_waypoint_position;
int round_counter;If you have already used the AWS DeepRacer, some parameters will look familiar to you. The environment also features a timer and a lap counter.
The RLDriver.cs script contains the reward function, which the user can customize to influence the agent's driving behavior. Once this has been changed according to the user's wishes, the training can be started. For this purpose, the behavior type of the session holder must be set to default. The actual training is started using the terminal.
Reward Function
There are a few things to consider when creating the reward function, which is called every frame and results in the cumulative reward after the episode length has elapsed. The maximum value of the function must not exceed 1 per call, otherwise unpredictable behavior occurs. Well, we learned that the hard way! ;-) The parameters used in the reward function should also be part of the observations passed to the Python interface. Based on the checkpoints, the progress on the track, the speed, whether the car is on the track or not and the distance to the current point to be passed, there are already many possibilities to combine. The great art is to give the parameters the correct weights via the function.
The approach we primarily took is to minimize distance towards the next checkpoint. The current run is stopped with a ‘death penalty’ if the car left the track. Added to this was a general penalty per call to increase speed in the long run. Finally, the track progress was added to the observed parameters.
We used the following function. The results can be seen in the final chapter.
private void ReawardFunction(){
AddReward(-0.001f);
if (!rLParameters.all_wheels_on_track){
AddReward(-1.0f);
EndEpisode();
return;
}
float distance = rLParameters.distance_to_next_waypoint;
if (distance > 20){
AddReward(0.03f);
}
else if (distance < 15){
AddReward(0.1f);
}
else if (distance < 10){
AddReward(0.3f);
}
if (rLParameters.waypoint_passed){
AddReward(1.00f);
}
}Alternatively, we used approaches to keep the distance to the center line small, but the models then tended to leave the route directly and take an illegal shortcut. During the project, we unfortunately did not succeed in bringing these parameters into a relationship where the network works well on our racetrack.
Problems
In order to use U-Race on your machine and to train your own neural networks, it is advisable to have a powerful computer. The computer should have more than 8 GB of RAM. While some training runs were aborted on Windows computers, they could be continued and the training completed. When using macOS, problems begun after just a few minutes of training as it can not be completed successfully. Unfortunately, the Docker connection was discontinued by ML Agents, which is why it was not possible for us to run the framework on Skynet. There is a headless mode with which it should be possible to initiate remote training. Some versions of the extensions used were not compatible with each other, which is why it was difficult to get a working version. Depending on the operating system, different versions were no longer accessible or no longer supported.
Results
Despite intensive training, we did not manage to get the agent to drive a whole lap on the racetrack. For a long time, the agent preferred to crawl slowly but backwards.
After experimenting, playing, observing and adjusting with the reward function and also 7 hours of training, it gained a lot of speed, but as soon as it had to brake hard into the first corner, it left the track.
Since the environment is functionally finished, you can try it yourself without experience in Unity.
In contrast to the AWS DeepRacer, you have an unlimited time to train your model, however you might need to install the required software and have the sufficient hardware. We would be pleased and honored, if a project based on U-Race will be continued in the upcoming terms.
Head over to GitHub to start your engines!