Use of LLMs as a Socratic teacher in the context of database teaching

The DBCoach (https://dbcoach.hs-kl.de/) is an interactive eLearning program at Kaiserslautern University of Applied Sciences that is designed to help users learn SQL and Java. As part of the course "Deep Learning", it was evaluated whether and how Large Language Models (LLM) can be connected to the service.
The objective is to provide an Al-supported Socratic teacher who answers questions not with the solution, but with hints and assistance on how to find the solution. The AI function is intended to take on a supporting role in the DBCoach, which should relieve the burden on teachers and improve/individualize support for students/users.
The models were selected with a focus on self-hosted models on the university's own infrastructure with the aim of being able to realize future use on the same hardware.
As part of the project, the following models in particular were included in the evaluation: llama3:70b-instruct, phi3:3.8b, mixtral:latest[1], mistral:latest[2] .
System environment & dataset
System environment & dataset
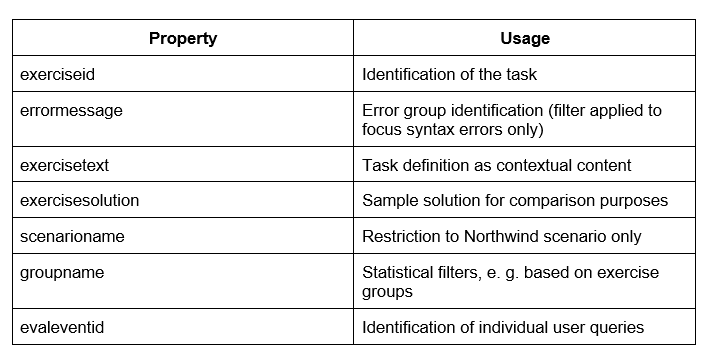
In order to enable flexible testing and evaluation independent of the DBCoach itself, a series of benchmark scripts were created to supplement manual sample tests. The testbenches implemented in Python 3 were used to quantify the results on the basis of the data set provided during the course. The data set is a deduction of the DB-Coach from all SQL user inputs of the year 2024 including associated context information, e.g. task, sample solution, etc. The following properties from the dataset were used for the evaluation:
Selection of the model
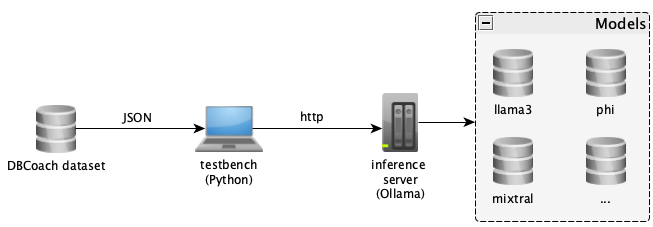
The common basis for the testbenches is the LangChain library, which provides an Ollama interface. The models were addressed via an inference server, which was also provided by a student working group from the context of the deep learning course.
As part of the evaluation, the following contextual areas were evaluated using the benchmark scripts:
- b0.py: Comparison of user input (guaranteed wrong due to syntax errors) and sample solution
- b1.py: Extraction of hints by the LLM based on user input and context, use of samples for prompting frameworks
- b2.py: Feedback loop (manual verification)
Due to the existing system environment (as shown in figure 1 above), the focus of the project was on connecting and evaluating the models and optimizing the prompting, but not on training the models for the intended usage scenario.
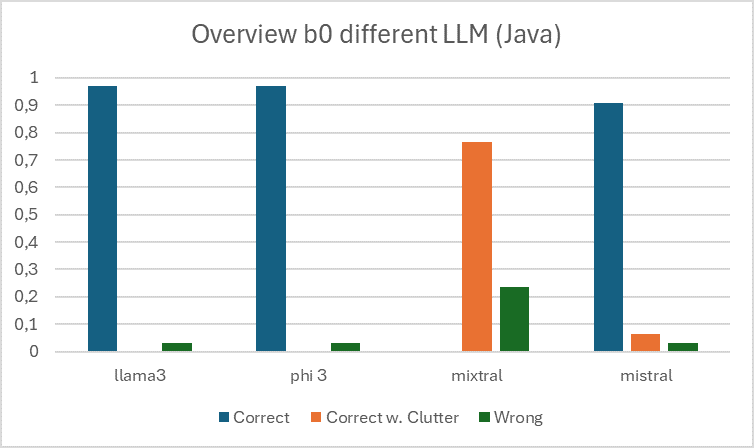
The starting point in the consideration of models was the selection of suitable models5 , for which a sample (n=500, scenario=Northwind, error text=SQL errors) was formed from the data set and fed to the models with the benchmark b0.
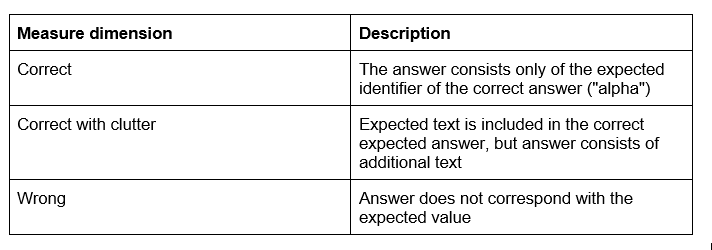
For quantification purposes, the benchmark b0 used a closed question to assess the correctness of two answers. One of the answers consisted of the sample solution, the other of the user query, which contains a syntax error based on the filter.
To simplify the extractions of answers, specific expressions were used here for the answer names/suffixes, for example in the form of "alpha" and "beta" instead of letters “a” and “b”. The measurements from Table below were used as the evaluation scale.
The results shown in figure below are based on the benchmark b0.
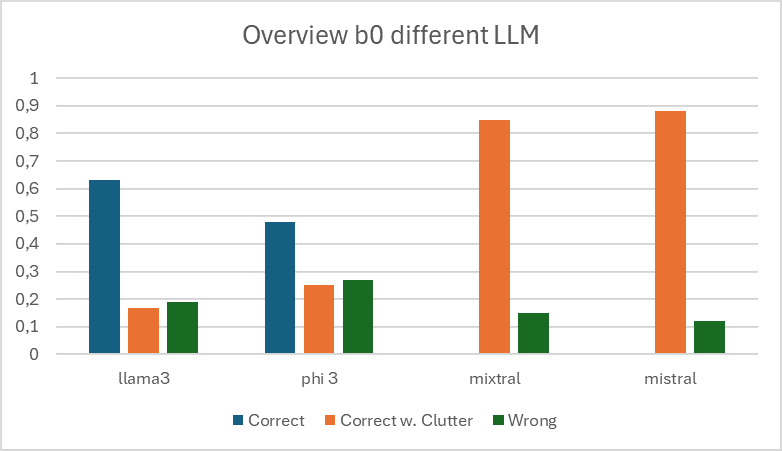
Using the following evaluation steps, the llama3:70b-instruct model was used on the basis of the results of b0. As part of the project, preference was given to models with results that had as little additional text (“clutter”) as possible in responses in order to evaluate options for programmatic processing of the information in the DBCoach at runtime. Due to the observed tendency of both mixtral and mistral, these models were excluded in subsequent benchmarks.
Challenges in prompting
When assessing models and measures, the focus was placed on the following evaluation dimensions to quantify results:
-
Correctness: The output must be correct.
-
Quality: As part of the evaluation, the quality of the output defines the frequency of hallucinations and the presence of excessively detailed answers ("clutter").
-
Format: As the output of the model must be fed to the DB Coach as a result, the precision and formatting of the result is an important aspect. Output as a list was always required. A list is defined here as a multi-line response, where one line corresponds to one value.
Each dimension was either scored as present or as absent per prompt response and model.
Prompting frameworks
The following section presents measures for the structural design of prompts to optimize LLM responses. Research was carried out into the approach to prompting, as a result of which several prompting approaches were identified. As an example, nine prompting approaches from (https://www.thomashutter.com/9-prompt-frameworks-fuer-chatgpt-gemini-copilot/.thomashutter.com/9-prompt-frameworks-fuer-chatgpt-gemini-copilot/) were applied
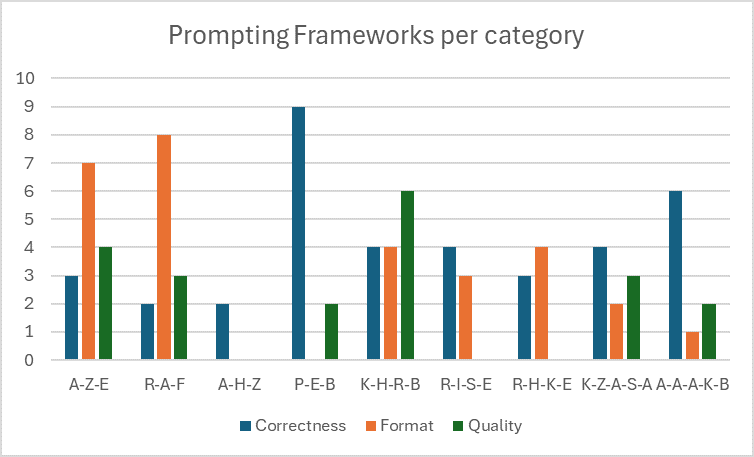
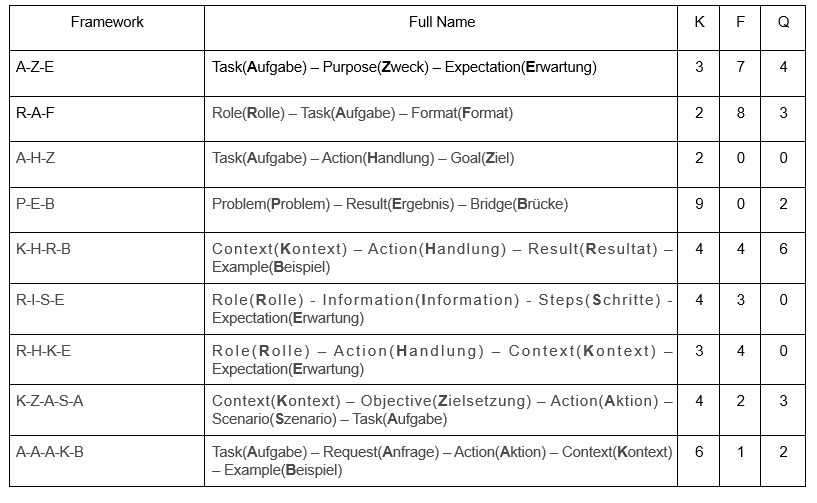
and quantified experimentally based on the measurement dimensions; a total of three points (one per dimension) can be achieved per dataset entry. The evaluation resulted in the performance data visualized in the figure and table below:
Interpretation: Prompting-Frameworks
A-H-Z showed that tested models focused strongly on the target aspect, which included two examples, each containing a problem and the corresponding solution in the desired format. In many cases, the errors from these examples were corrected instead of referring to the task, which is why the "correctness" and "quality" aspects scored comparatively poorly.
P-E-B & A-A-A-K-B delivered comparatively good results. As a core issue the approaches showed that the user query was not taken into account when answering. This logically leads to a poor result in the "quality" area, as simply providing the sample solution does not correspond to the orientation of Socratic learning.
R-I-S-E & R-H-K-E & A-A-A-K-B often provided answers in English, which did not meet the original requirement and was therefore considered a fail in terms of "quality".
Some of the evaluated frameworks use examples that therefore move away from classic (zero-shot) prompting and are therefore referred to as few-shot. A significant improvement through this prompting strategy could not be determined. It can be observed that prompting frameworks that use a context generally show better results in terms of correctness, while contextless ones tend to perform better in terms of format and quality.
Use of a feedback loop
The results from b1, consisting of the data set supplied and the statements identified by the model, were fed into benchmark b2 as a sample (n=10). The aim of benchmark b2 is to quantify the statements provided by the LLM. Hereby, the statements consist out of programmatically extracted information, thus requiring a high format accuracy from the model. If the response could not be identified as such due to inadequate format, the feedback loop was omitted.
b2 as a benchmark is used to identify semantically and substantively incorrect statements.
The use of the K-H-R-B (Context(Kontext) - Action(Handlung) - Result(Resultat) - Example(Beispiel) prompting framework served as the textual basis here. While other prompting approaches scored high in some, categories, this approach featured similar results in all measurement dimensions.
The dataset from the listing below for the b2 benchmark supplements the prompt originally fed to the LLM, the task context and statements (below listed as extracted_errors), as well as the original user query in conjunction with the response of the first iteration.
{
"exercise_id": "Task identifier",
"training_query": "User query",
"scenario_name": "Name of the scenario",
"reported_error": "Error on the part of DBCoach/ SQL Server",
"prompt": "Original prompt",
"response": "Response of the LLM to the prompt",
"extracted_errors": [],
},
The original prompt was adapted in the feedback loop iteration in order to assess the statements returned by the LLM (extracted_errors) instead of a paraphrase of the existing problems. The evaluation was carried out for each element of the list using a yes/no methodology. Data records for which no errors could be identified due to format deviations were skipped in the sample and not evaluated separately as the focus of b2 is in measuring changes to the results given from previous prompt responses. Results where the format did not match the expected response mode were not scored (zero scoring).
Using the Confusion Matrix visualized in Figure below as a basis for evaluation, the results visualized in Figure “error judging” coud be obtained.


In a random sample (see Figure Z), the use of a feedback loop continued to show a high susceptibility to hallucinations.
In only a few cases (n=2) was the feedback loop able to identify true positives (TP)/ or true negatives (TN). Data sets 4, 8-10 could not be included in the numerical evaluation as the LLM was unable to provide any evaluable results due to format requirements.
Interpretation: Due to the fact that in half of the cases the feedback loop (further) worsens the results, it can be assumed that this is not a useful approach to significantly improve the response quality.
Abstraction to other scenarios
As part of the project, the similar application of LLM was tested on a secondary use case of the DB Coach, which consists of the evaluation of Java code. The approach for determining the result corresponds to the SQL b0 procedure.
Initially, a very small sample of n=64 was used. This sample was selected for a single task, which consisted of a "Hello World" program. Furthermore, each program contains compile errors, which ensures that answer beta in the b0 benchmark can always be assumed to be false with certainty.
The same test was then carried out with an extended sample of n=580. Furthermore, each date contains either a compile or runtime error.
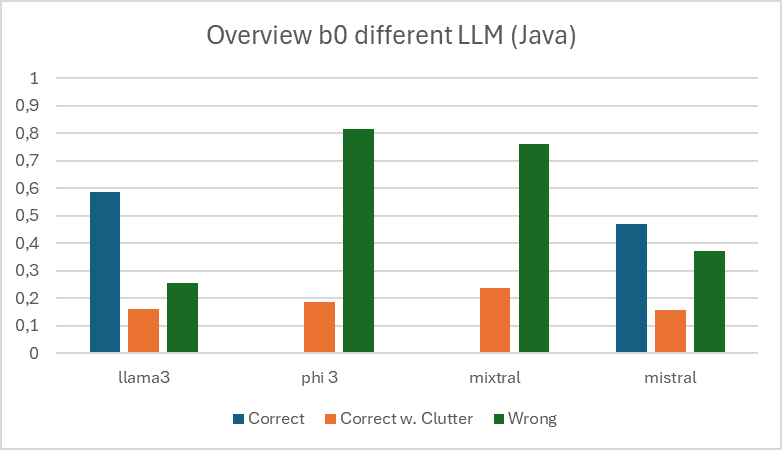
Interpretation: A clear deterioration in the results of all LLMs can be observed. For example, llama3 falls from previously >90% to less than 60% correctness rate. In short: Due to the "increasing" complexity of the programs, the performance of the individual LLMs drops drastically to an unsatisfactory level.
Summary
The project showed that the available set of LLMs are only suitable to a limited extent in the desired usage scenario. Based on available models, the models showed different strengths in the defined quality dimensions. In particular, the presence of clutter and hallucinations creates the risk of false conclusions for the user, who as a student, for example, can only assess the statements of such a model to a limited extent.
The deviation from format specifications in the prompt makes further processing by the a consuming software (thus - DBCoach) more difficult, so that integration is only possible with additional effort by having to parse the output again.
In summary, it must be stated that the use of large language models in their current form is not recommended. A possible extension of this research is the evaluation of models after a scenario-targeted training phase based on similar qualitative measurements.
Based on quality measurements, it is also advisable to develop your own evaluation schemes tailored on the desired usage scenario in order to be able to measure the performance of the LLM rather than rating the models only based on official publication performance information.
[1] Current checkpoint at time of writing
[2] Current checkpoint at time of writing